
In this post, we’ll go through the MaskFormer and Mask2Former models created for segmentation purposes. We give a simple introduction to image segmentation and Mask2Fomer architecture first. However, the main aim is to showcase the implementation of such a model using TensorFlow and HuggingFace. The tools and libraries you’ll need for this project are:IDE:Libraries:We are assuming that you are familiar with deep learning with Python and Jupyter notebooks. If you're new to Python, start with this tutorial. And if you aren't yet familiar with Jupyter, start here.
In this post, we’ll go through the MaskFormer and Mask2Former models created for segmentation purposes. We give a simple introduction to image segmentation and Mask2Fomer architecture first. However, the main aim is to showcase the implementation of such a model using TensorFlow and HuggingFace.
The tools and libraries you’ll need for this project are:
IDE:
Libraries:
We are assuming that you are familiar with deep learning with Python and Jupyter notebooks. If you're new to Python, start with this tutorial. And if you aren't yet familiar with Jupyter, start here.
Image Segmentation
Image segmentation is a method of breaking down an image into various subgroups called Image segments, which helps to reduce the complexity of the image and make subsequent processing or analysis of the image easier. Image segmentation is the practice of categorizing image pixels.
Segmentation Types
Semantic segmentation is a computer vision task that labels each pixel in an image with a predefined set of classes.
Instant Segmentation is a computer vision task that involves detecting instances of objects in an image and labeling them.
Panoptic segmentation is a task in computer vision that combines semantic and instance segmentation.
Let's take a look at the Mask2Former algorithm, which can be used to perform all types of segmentation.

Mask2Former
Masked-attention Mask Transformer for Universal Image Segmentation is the full name of mask2former. It is a general-purpose architecture for panoptic, instance, and semantic segmentation. Masked attention, which extracts localized features by constraining cross-attention within predicted mask regions, is one of its key components. On four popular datasets, this model outperforms the best-specialized architectures by a wide margin. Mask2Former, in particular, establishes new benchmarks for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO), and semantic segmentation (57.7 mIoU on ADE20K).
With DETR (DEtection TRansformer), universal architectures have emerged, demonstrating that mask classification architectures with an end-to-end set prediction objective are general enough for any image segmentation task. MaskFormer demonstrates that mask classification based on DETR not only performs well in panoptic segmentation but also performs well in semantic segmentation. K-Net goes beyond set prediction to include instance segmentation. Unfortunately, these architectures do not succeed in replacing specialized models because their performance on specific tasks or datasets is still inferior to the best-specialized architecture (e.g.,MaskFormer cannot segment instances well which is shown in the image below). Mask2Former is the first architecture to outperform state-of-the-art specialized architectures across all tasks and datasets considered.
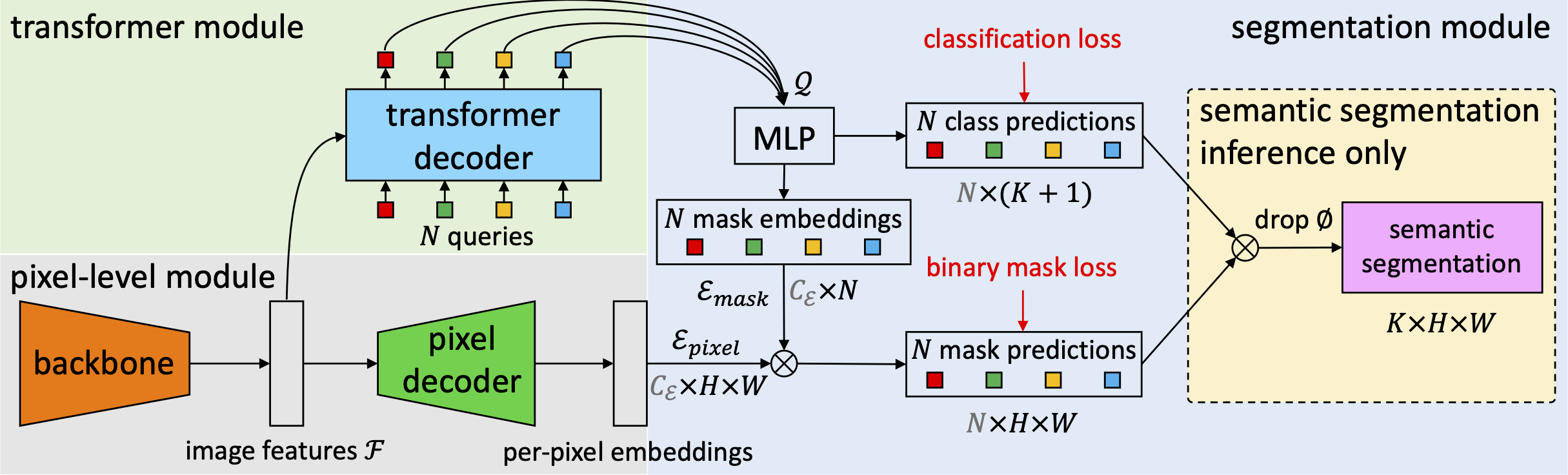
How to Use Mask2Former Segmentation Model
Training a MaskFormer segmentation model with Hugging Face Transformers can be done using the following steps:
- Data Preparation: The first step is to prepare your data. You will need a dataset that contains images and their corresponding masks. The masks should have the same dimensions as the images and have the same number of channels (usually one for grayscale and three for RGB). You can use tools such as OpenCV or PIL to read and preprocess the images.
- Tokenization: Next, you will need to tokenize your data using Hugging Face's tokenizer. This will convert your images and masks into a sequence of tokens that can be processed by the MaskFormer model. You can use Hugging Face's 'AutoTokenizer' to automatically select the appropriate tokenizer for your model.
- Model Preparation: After tokenizing the data, you will need to prepare the Mask2Former model for training. You can use Hugging Face's 'AutoModelForMaskedImageClassification' to automatically select the appropriate Mask2Former model for your task. You will also need to specify the number of classes (in this case, two: foreground and background) and the learning rate for the optimizer.
- Training: Once the model is prepared, you can start training. You will need to define a training loop that iterates over the training data, calculates the loss, and updates the model parameters. You can use Hugging Face's Trainer class to automate this process.
- Evaluation: After training, you will need to evaluate the performance of your model on a validation set. You can use Hugging Face's 'Trainer.evaluate' method to do this.
- Inference: Finally, you can use your trained model for inference on new images. You will need to tokenize the new images and pass them through the model to generate masks.
These steps provide a general outline of how to train a MaskFormer segmentation model with Hugging Face Transformers. The exact implementation details will depend on your specific task and dataset. Hugging Face's documentation provides detailed examples and tutorials for training and using MaskFormer models.
from transformers import AutoImageProcessor, MaskFormerForInstanceSegmentation
from PIL import Image
import requests
# load MaskFormer fine-tuned on ADE20k semantic segmentation
image_processor = AutoImageProcessor.from_pretrained("facebook/maskformer-swin-base-ade")
model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-ade")
url = (
"https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg"
)
image = Image.open(requests.get(url, stream=True).raw)
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to image_processor for postprocessing
predicted_semantic_map = image_processor.post_process_semantic_segmentation(
outputs, target_sizes=[image.size[::-1]]
)[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
list(predicted_semantic_map.shape)Here is an example of Panoptic segmentation:
from transformers import AutoImageProcessor, MaskFormerForInstanceSegmentation
from PIL import Image
import requests
# load MaskFormer fine-tuned on COCO panoptic segmentation
image_processor = AutoImageProcessor.from_pretrained("facebook/maskformer-swin-base-coco")
model = MaskFormerForInstanceSegmentation.from_pretrained("facebook/maskformer-swin-base-coco")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts class_queries_logits of shape `(batch_size, num_queries)`
# and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
class_queries_logits = outputs.class_queries_logits
masks_queries_logits = outputs.masks_queries_logits
# you can pass them to image_processor for postprocessing
result = image_processor.post_process_panoptic_segmentation(outputs, target_sizes=[image.size[::-1]])[0]
# we refer to the demo notebooks for visualization (see "Resources" section in the MaskFormer docs)
predicted_panoptic_map = result["segmentation"]
list(predicted_panoptic_map.shape)
Comments
Post a Comment