
VideoMAE is a self-supervised video pre-training method that uses masked autoencoders to learn data-efficient video representations. The method is based on video masking with a high ratio, which improves the performance of video reconstruction and the generalization of video representations on small datasets. The authors of the paper show that VideoMAE is a data-efficient learner for self-supervised video pre-training, and that it can achieve impressive results on very small datasets without using any extra data. The code for VideoMAE is available on GitHub.

What is a Masked Encoder
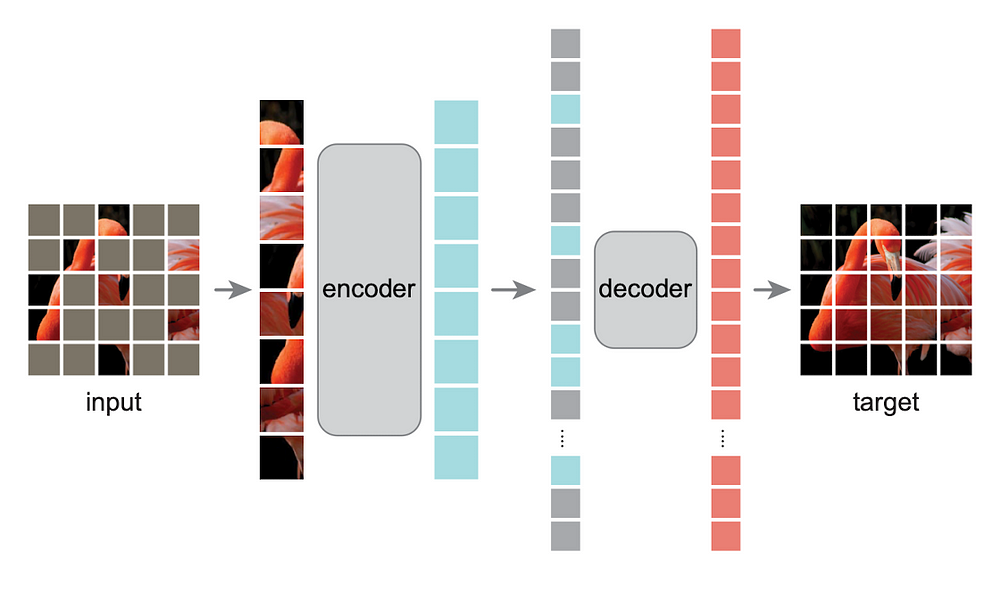
A masked autoencoder is a type of neural network that can learn to extract and map meaningful latent representations into high-dimensional space from data by training on large datasets of input samples. The method is based on masking random patches of the input image and reconstructing the missing pixels. It is based on two core designs: an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Masked autoencoders are scalable self-supervised learners for computer vision and can be used to improve the performance of video reconstruction and the generalization of video representations on small datasets.
Here is the Github Implementation of MAE.
How to Use VideoMAE Pre-Trained Model from HuggingFace
import torch
from transformers import VideoMAEFeatureExtractor, VideoMAEModel
# Load the VideoMAE feature extractor
feature_extractor = VideoMAEFeatureExtractor.from_pretrained('facebookresearch/videomae')
# Load the VideoMAE model
model = VideoMAEModel.from_pretrained('facebookresearch/videomae')
# Define a video input
video_input = torch.randn(1, 3, 16, 224, 224)
# Extract features from the video
features = feature_extractor(video_input)
# Pass the features through the VideoMAE model
output = model(features)
# Print the output
print(output)How to FineTune VideoMAE on a Custom Dataset
import torch
from transformers import VideoMAEModel, VideoMAEFeatureExtractor
# Load the pre-trained VideoMAE model
model = VideoMAEModel.from_pretrained('facebookresearch/videomae')
# Replace the classification head of the model
model.classifier = torch.nn.Linear(model.config.hidden_size, num_classes)
# Load your dataset and prepare it for training
train_dataset = MyDataset(...)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Define the optimizer and loss function
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
loss_fn = torch.nn.CrossEntropyLoss()
# Fine-tune the model on your dataset
for epoch in range(num_epochs):
for batch in train_loader:
inputs, labels = batch
features = feature_extractor(inputs)
outputs = model(features)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Evaluate the performance of the fine-tuned model on a validation set
val_dataset = MyDataset(...)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
with torch.no_grad():
correct = 0
total = 0
for batch in val_loader:
inputs, labels = batch
features = feature_extractor(inputs)
outputs = model(features)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print('Validation accuracy: {:.2f}%'.format(accuracy))
Comments
Post a Comment