
Q-learning is a popular reinforcement learning algorithm used to make decisions in an environment. It enables an agent to learn optimal actions by iteratively updating its Q-values, which represent the expected rewards for taking certain actions in specific states. Here is a step-by-step implementation of Q-learning using Python:
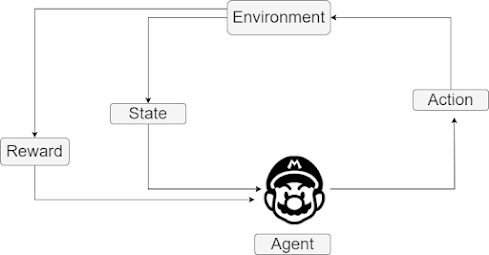
Image by Author
1. Import the necessary libraries:
import numpy as np
import random2. Define the environment:
# Define the environment
env = np.array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
# Define the rewards
rewards = np.array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
# Define the actions
actions = ['up', 'down', 'left', 'right']3. Define the Q-table:
# Define the Q-table
q_table = np.zeros([env.shape[0], env.shape[1], len(actions)])4. Define the hyperparameters:
# Define the hyperparameters
alpha = 0.1
gamma = 0.6
epsilon = 0.15. Define the training loop:
# Define the training loop
for episode in range(1, 1001):
state = [0, 0]
while state != [9, 9]:
if random.uniform(0, 1) < epsilon:
action = random.choice(actions)
else:
action = actions[np.argmax(q_table[state[0], state[1]])]
if action == 'up':
next_state = [max(state[0] - 1, 0), state[1]]
elif action == 'down':
next_state = [min(state[0] + 1, 9), state[1]]
elif action == 'left':
next_state = [state[0], max(state[1] - 1, 0)]
else:
next_state = [state[0], min(state[1] + 1Neural Network with Q-learning
Neural networks can be used in Q-learning to approximate the Q-values of each state-action pair. This is known as Deep Q-Learning. Here’s how to use a neural network with Q-learning:
1. Define the neural network architecture:
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(64, input_shape=(state_size,), activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(action_size, activation='linear')
])2. Define the hyperparameters:
# Define the hyperparameters
alpha = 0.1
gamma = 0.6
epsilon = 0.13. Define the training loop:
# Define the training loop
for episode in range(1, 1001):
state = env.reset()
state = np.reshape(state, [1, state_size])
done = False
while not done:
if np.random.rand() <= epsilon:
action = random.randrange(action_size)
else:
q_values = model.predict(state)
action = np.argmax(q_values[0])
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
target = reward + gamma * np.amax(model.predict(next_state)[0])
q_values = model.predict(state)
q_values[0][action] = (1 - alpha) * q_values[0][action] + alpha * target
model.fit(state, q_values, verbose=0)
state = next_state4. Evaluate the model:
# Evaluate the model
scores = []
for episode in range(100):
state = env.reset()
state = np.reshape(state, [1, state_size])
done = False
score = 0
while not done:
q_values = model.predict(state)
action = np.argmax(q_values[0])
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
score += reward
state = next_state
scores.append(score)
print(np.mean(scores))In this implementation, we use a neural network with two hidden layers of 64 neurons each and a linear output layer with the same number of neurons as the number of actions. The neural network is trained using the Q-learning algorithm, which updates the Q-values of each state-action pair based on the Bellman equation. The hyperparameters alpha, gamma, and epsilon control the learning rate, discount factor, and exploration rate, respectively.
Comments
Post a Comment