
In this post, we will discuss building a multi-head attention layer in a Transorfmer, which is a more advanced variant of the attention layer that has proven to be very effective in practice. Moreover, we will show you how to implement such Layer using Pytorch.
Building a Multi-Head Attention Layer in a Transformer
The Transformer is a powerful neural network architecture that has achieved state-of-the-art performance on a variety of natural language processing tasks. One key component of the Transformer is the attention layer, which allows the model to focus on specific parts of the input while processing it.
The Attention Mechanism
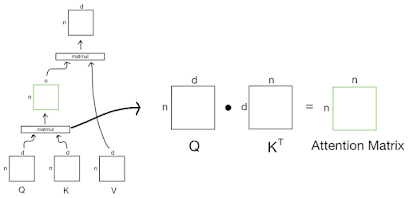
At a high level, the attention mechanism works by allowing the model to "pay attention" to different parts of the input while processing it. This is done by first projecting the input and key-value pairs using linear transformations, and then computing the attention weights using a dot product between the projected input and the keys. These attention weights are then used to weight the value vectors, which are then summed to produce the output of the attention layer.
Formally, given input vectors $X = {x_1, x_2, ..., x_n}$, key-value pairs $K = {k_1, k_2, ..., k_n}$, and value vectors $V = {v_1, v_2, ..., v_n}$, the attention layer computes the output Y as follows:
$$Y = \sum_{i=1}^{n} a_i v_i$$
where the attention weights a_i are computed as:
$a_i = \frac{\exp(x_i \cdot k_i)}{\sum_{j=1}^{n} \exp(x_j \cdot k_j)}$
This attention mechanism is known as "dot-product attention".
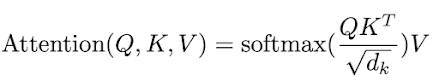
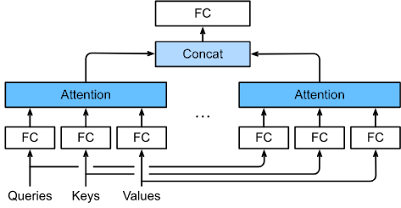
Multihead Attention
While the attention mechanism described above is effective, it has a few limitations. One limitation is that it only allows the model to attend to a single part of the input at a time. This can be limiting, as there may be multiple important parts of the input that the model needs to consider simultaneously.
To address this issue, we can use the concept of "multi-head attention". In multi-head attention, we project the input, key, and value vectors multiple times using different linear transformations, and then compute multiple attention weights using these projected vectors. These attention weights are then concatenated and once again projected using a linear transformation to produce the final output of the attention layer.
Formally, given input vectors $X$, key-value pairs $K$, and value vectors $V$, the multi-head attention layer computes the output Y as follows:
$W_o$, $W_{i,Q}$, $W_{i,K}$, and $W_{i,V}$
where $head_i$ is the output of the attention mechanism applied to the projected input, keys, and values:
$head_i = Attention(XW_{i,Q}, KW_{i,K}, VW_{i,V})$
and $W_o$, $W_{i,Q}$, $W_{i,K}$, and $W_{i,V}$, are learned linear transformations.
Implementation
Now that we have a high-level understanding of how multi-head attention works, let's look at how we can implement it in code. We will be using PyTorch as our deep learning framework, but the concepts should be applicable to other frameworks as well.
First, let's define some input data and the number of heads that we want to use:
import torch
# Input data
X = torch.randn(batch_size, seq_len, dim)
K = torch.randn(batch_size, seq_len, dim)
V = torch.randn(batch_size, seq_len, dim)
# Number of heads
h = 8Next, we will define the linear transformations that we will use to project the input, keys, and values. These transformations will have the following dimensions:
- $W_{i,Q} \in \mathbb{R}^{d_{model} \times d_k}$
- $W_{i,K} \in \mathbb{R}^{d_{model} \times d_k}$
- $W_{i,V} \in \mathbb{R}^{d_{model} \times d_v}$
- $W_o \in \mathbb{R}^{hd_v \times d_{model}}$
Where $d_{model}$ is the dimensionality of the input and output, $d_k$ is the dimensionality of the keys, and $d_v$ is the dimensionality of the values.
# Linear transformations
W_Q = torch.randn(h, dim, dim_k)
W_K = torch.randn(h, dim, dim_k)
W_V = torch.randn(h, dim, dim_v)
W_O = torch.randn(h * dim_v, dim)With these linear transformations defined, we can now implement the multi-head attention layer. We will do this in two steps:
- Compute the attention weights for each head and apply them to the values
- Concatenate the resulting value vectors and apply the final linear transformation
Here is the code to do this:
# Step 1: Compute attention weights and apply them to the values
attention_outputs = []
for i in range(h):
# Project input, keys, and values
X_proj = X.matmul(W_Q[i])
K_proj = K.matmul(W_K[i])
V_proj = V.matmul(W_V[i])
# Compute attention weights
weights = torch.softmax(X_proj.matmul(K_proj.transpose(-2, -1)) / math.sqrt(dim_k), dim=-1)
# Apply attention weights to values
head_output = torch.sum(weights.unsqueeze(-1) * V_proj, dim=1)
attention_outputs.append(head_output)
# Step 2: Concatenate and apply final linear transformation
Y = torch.cat(attention_outputs, dim=1).matmul(W_O)That's it! We have now implemented a multi-head attention layer in PyTorch.
Conclusion
In this post, we learned about the attention mechanism and how it can be used to allow a model to focus on specific parts of the input while
Comments
Post a Comment