Cutting-edge computer vision models, often referred to as state-of-the-art (SotA) models, exhibit a limitation in their comprehension of the visual world, primarily shaped by their training data [1].
While these models excel in specific tasks and datasets, their ability to generalize is limited. They struggle with novel categories or images that fall outside the scope of their original training domain.
This brittleness can pose challenges when creating specialized image classification applications, such as identifying defects in agricultural products or detecting counterfeit banknotes to combat fraud. Gathering sufficiently large labeled datasets for fine-tuning conventional computer vision models in these niche areas can be exceptionally challenging.
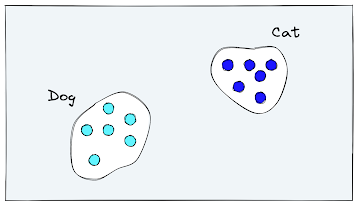
Ideally, a computer vision model should learn to grasp the content of images without fixating excessively on the specific labels it was initially trained on. For instance, when presented with an image of a dog, the model should not only recognize the dog but also understand contextual details like the presence of trees in the background, the time of day, and the dog's location on a grassy field.
Regrettably, the outcome of classification training contradicts this ideal. Models tend to group their internal representations of dogs into a designated "dog vector space" and cats into a designated "cat vector space." Their focus becomes binary, centered on determining whether an image aligns with a specific class or not.
While retraining classification models is a viable option, it demands substantial investments of time and resources for both dataset collection and the actual model training process.
Thankfully, OpenAI's CLIP has demonstrated remarkable versatility as a classification model, frequently eliminating the need for retraining altogether. In this section, we will delve into the realm of zero-shot image classification using CLIP.
N-Shot Learning
Before diving into CLIP, let’s take a moment to understand what exactly “zero-shot” is and its significance in ML.
The concept derives from N-shot learning. Here we define N as the number of samples required to train a model to begin making predictions in a new domain or on a new task.
Many SotA models today are pretrained on vast amounts of data like ResNet or BERT. These pretrained models are then fine-tuned for a specific task and domain. For example, a ResNet model can be pretrained with ImageNet and then fine-tuned for clothing categorization.
Models like ResNet and BERT are called “many-shot” learners because we need many training samples to reach acceptable performance during that final fine-tuning step.
Many-shot learning is only possible when we have compute, time, and data to allow us to fine-tune our models. Ideally, we want to maximize model performance while minimizing N-shot requirements.
Zero-shot is the natural best-case scenario for a model as it means we require zero training samples before shifting it to a new domain or task.
CLIP may not be breaking SotA performance benchmarks on specific datasets. Still, it is proving to be a massive leap forward in zero-shot performance across various tasks in both image and text modalities.
The point of CLIP is not SotA performance. However, it’s worth noting that CLIP did beat the previous SotA results on the STL10 benchmark despite never being trained on that dataset.
The zero-shot adaptability of CLIP was found to work across many domains and different tasks. We will be talking about image classification in this article, but it can also be used in multi-modal search/recommendation, object detection, and likely many more as of yet unknown tasks.
How CLIP Makes Zero-Shot So Effective?
Contrastive Language-Image Pretraining (CLIP) is a predominantly transformer-based model introduced by OpenAI in 2021 [1].
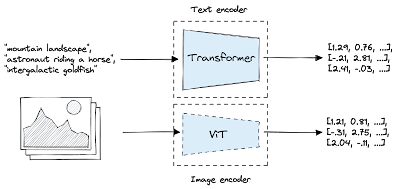
CLIP is composed of two models, as elaborated on in the preceding chapter. The iteration of CLIP utilized in this context incorporates a text transformer for the encoding of text embeddings and a vision transformer (ViT) for the encoding of image embeddings.
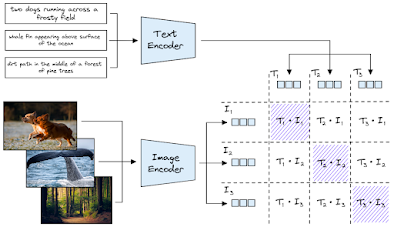
Both CLIP models undergo optimization during the pretraining phase to ensure the alignment of similar text and images within a vector space. This is achieved by processing image-text pairs and bringing their output vectors closer together in the vector space while creating separation between the vectors of non-pairs.
CLIP distinguishes itself from typical classification models through several key characteristics. Firstly, it was trained on an extensive dataset comprising 400 million text-image pairs collected from various sources on the internet.
This approach offers three significant advantages:
CLIP operates effectively with image-text pairs, eliminating the need for specific class labels due to its contrastive training approach rather than a classification-focused one. In today's social-media-centric environment, such data is readily available.
The extensive dataset size allows CLIP to develop a robust understanding of general textual concepts found within images.
Text descriptors often encompass multiple aspects of an image, providing a more comprehensive representation of both images and text.
These benefits are pivotal in explaining CLIP's remarkable zero-shot performance.
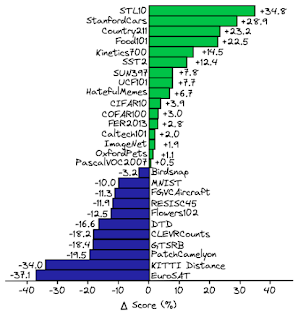
The authors of CLIP provide a compelling illustration of this by comparing the performance of a ResNet-101 model, trained specifically on ImageNet, with CLIP when both models are applied to other datasets derived from ImageNet.
In this comparison, it becomes evident that despite ResNet-101 being trained on ImageNet, its performance on similar datasets is considerably inferior to CLIP's performance on the same tasks. CLIP demonstrates superior performance compared to a State-of-the-Art (SotA) model trained specifically for ImageNet, even when applied to slightly modified ImageNet tasks.
When employing a ResNet model in different domains, a common approach involves using a "linear probe." This entails utilizing the features learned by the ResNet, typically from the last few layers, and inputting them into a linear classifier that is fine-tuned for a specific dataset. This process can be considered as transitioning from few-shot to many-shot learning.
In the CLIP research, a linear probe ResNet-50 was compared to zero-shot CLIP. Remarkably, in one scenario, zero-shot CLIP surpasses linear probing across numerous tasks, highlighting its exceptional performance and versatility.
Despite CLIP not being trained for these specific tasks, it outperforms a ResNet-50 with a linear probe. However, it’s worth noting that zero-shot did not outperform linear probing when given more training samples.
Python Implementation of CLIP
Let’s move on to an applied example of CLIP for zero-shot classification. We will use the frgfm/imagenette dataset via Hugging Face Datasets.
# import the imagenette dataset
from datasets import load_dataset
imagenette = load_dataset(
'frgfm/imagenette',
'320px',
split='validation',
revision="4d512db"
)
# show dataset info
imagenette
# check labels in the dataset
set(imagenette['label'])
The dataset comprises 10 labels, all represented as integer values. To conduct classification using CLIP, we require the textual descriptions corresponding to these labels. Fortunately, in most Hugging Face datasets, you can find the mapping to text labels conveniently within the dataset information.
# labels names
labels = imagenette.info.features['label'].names
labels
# generate sentences
clip_labels = [f"a photo of a {label}" for label in labels]
clip_labelsBefore we can proceed to compare labels and photos, we must initialize CLIP. For this purpose, we will utilize the CLIP implementation available through Hugging Face transformers.
# initialization
from transformers import CLIPProcessor, CLIPModel
model_id = "openai/clip-vit-base-patch32"
processor = CLIPProcessor.from_pretrained(model_id)
model = CLIPModel.from_pretrained(model_id)
import torch
# if you have CUDA set it to the active device like this
device = "cuda" if torch.cuda.is_available() else "cpu"
# move the model to the device
model.to(device)
device
Text transformers do not directly process text; rather, they require a set of integer values referred to as token IDs or input_ids. Each unique integer in this set represents a word or sub-word, which is known as a token.
To generate these token IDs and create another tensor called the attention mask (utilized by the transformer's attention mechanism), we will employ the processor we initialized earlier.
# create label tokens
label_tokens = processor(
text=clip_labels,
padding=True,
images=None,
return_tensors='pt'
).to(device)
label_tokens['input_ids'][0][:10]
# encode tokens to sentence embeddings
label_emb = model.get_text_features(**label_tokens)
# detach from pytorch gradient computation
label_emb = label_emb.detach().cpu().numpy()
label_emb.min(), label_emb.max()
The vectors produced by CLIP are not normalized by default. This means that using dot product similarity to compare these vectors can yield inaccurate results unless the vectors are normalized beforehand. The normalization process can be carried out as follows:
import numpy as np
# normalization
label_emb = label_emb / np.linalg.norm(label_emb, axis=0)
label_emb.min(), label_emb.max()
Now, we need to follow the same process for the images in our dataset. Let's begin by testing this process with a single image first.
imagenette[0]['image']
label_emb.shape
image = processor(
text=None,
images=imagenette[0]['image'],
return_tensors='pt'
)['pixel_values'].to(device)
image.shape
After processing the image, we obtain a single image with three color channels (RGB) and dimensions of 224 pixels in width and 224 pixels in height. This processing is necessary to normalize and resize the images to match the input size expected by the ViT model.
To create the image embedding, you can use the following code:
img_emb = model.get_image_features(image)
img_emb.shape
img_emb = img_emb.detach().cpu().numpy()
scores = np.dot(img_emb, label_emb.T)
scores.shape
# get index of highest score
pred = np.argmax(scores)
pred
# find text label with highest score
labels[pred]


Comments
Post a Comment