
In natural language processing (NLP) and computer vision (CV), one of the most critical aspects of deep learning is the use of neural networks. These neural networks are responsible for transforming raw data into meaningful representations. In NLP and CV, the data is in the form of text, images, or videos, and each of these data types requires a different representation.
In NLP, the most common representation of text is embedding. An embedding is a dense vector that represents the meaning of a word or phrase. The embedding is learned by the neural network during training, and it is used as input to the network for downstream tasks like sentiment analysis, text classification, or machine translation. However, the text is a sequential data type, and the order of the words in a sentence is crucial to its meaning. This is where position embedding comes in.
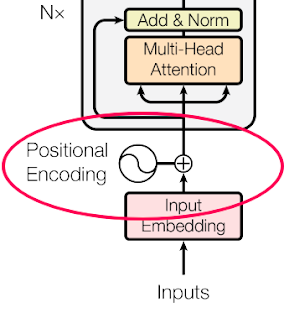
What is Position Embedding?
Position embedding is a technique used in NLP to embed the position of each word in a sentence along with its meaning. In other words, it is a way to represent the sequential order of the words in a sentence. Position embedding is a critical component of transformer-based architectures like BERT, GPT-2, and RoBERTa, which are currently state-of-the-art in NLP.
In traditional neural networks, the input to the network is a fixed-size vector, and the order of the data is not taken into account. In NLP, this is problematic because the meaning of a sentence can change based on the order of the words. For example, the sentences "The cat sat on the mat" and "The mat sat on the cat" have very different meanings. This is where position embedding becomes important.
Position embedding adds a position vector to each word embedding, which represents the position of the word in the sentence. The position vector is learned during training, and it is added to the word embedding to form the final input vector to the neural network. This way, the neural network can take into account the order of the words in a sentence.
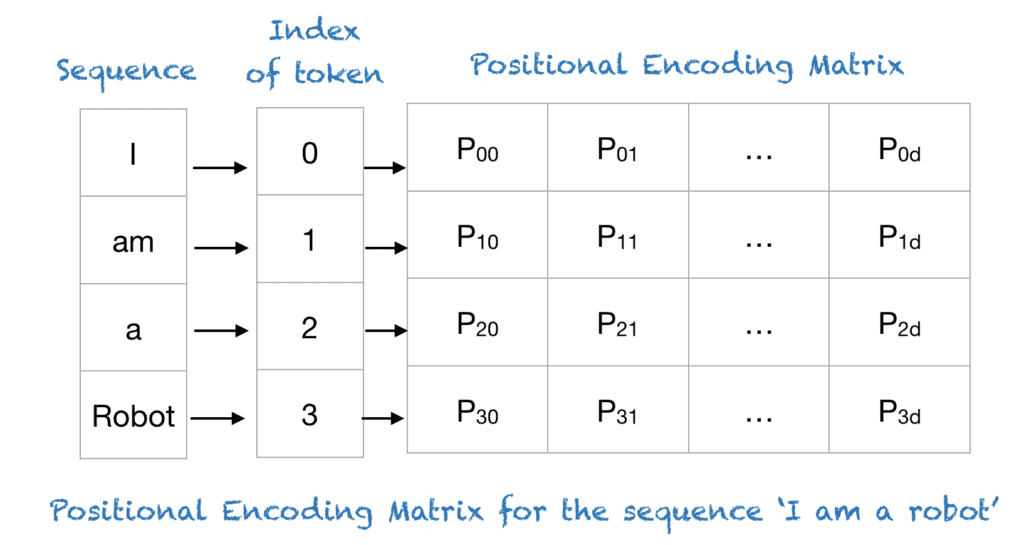
How Does Position Embedding Work?
Position embedding works by adding a position vector to each word embedding. The position vector is a fixed-size vector that represents the position of the word in the sentence. The position vector is added to the word embedding to form the final input vector to the neural network.
The position vector is generated using a mathematical function called a positional encoding function. The positional encoding function takes two inputs: the position of the word in the sentence and the dimension of the embedding. The output of the positional encoding function is a fixed-size vector that represents the position of the word in the sentence.
There are different positional encoding functions used in transformer-based architectures, but the most common one is the sine and cosine function. The sine and cosine function produces a periodic function that varies with the position of the word in the sentence. This function is then concatenated with the word embedding to form the final input vector.
Let's look at an example to understand how to position embedding works. Consider the sentence "The cat sat on the mat." The word "cat" has an embedding vector of [0.1, 0.2, 0.3], and its position in the sentence is 2. The position vector for the word "cat" is generated using the positional encoding function, which takes the position of the word and the dimension of the embedding as inputs. The position vector for the word "cat" is [0.84, 0.53, 0.00], and it is added to the word embedding to form the final input vector [0.94, 0.73, 0.3]. The same process is repeated for each word in the sentence. The figure belwo shows an example:
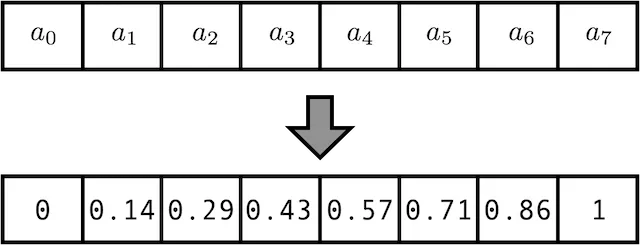
But wait! We've introduced a new issue. We can't deal with arbitrary sequence lengths anymore. This is because each of these entries is divided by the length of the sequence. A positional encoding value of 0.8, for example, means something completely different to a sequence of length 5 than it does to one of length 20. (For a length of 5, 0.8=4/5, indicating that it is the fourth element. For a sequence length of 20, 0.8=16/20 denotes the 16th element!). With variable sequence lengths, naively normalizing does not work.
What we need to be able to do is count without ever using a number greater than one. That's a big hint, and you might be able to figure it out.
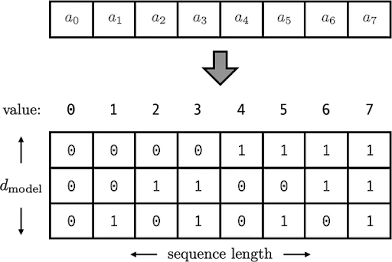
Instead of writing 35 for the 35th element, we could use the binary form 100011 instead. That's right, everything is less than one. But, in our excitement, we forgot that the number 35 is the same in binary and decimal; it's always just 35. We gained nothing... Instead, we must complete two tasks: 1) convert our integer to binary, and 2) transform our scalar to a vector.
What the heck, scalar to vector? What does this imply? This means that our positional encoding vector has been transformed into a positional encoding matrix. Instead of just an integer, each number gets its own binary vector. This is a significant conceptual shift, but by increasing the dimensionality, we can keep arbitrary long sequences, and at the same time restrict numbers to the range [0,1]! Our encoding now looks like this:
Benefits of Position Embedding
- Better Representation of Sequential Data
As mentioned earlier, position embedding enables neural networks to consider the order of words in a sentence. This helps the neural network to create a better representation of the sequential data, which is especially important in NLP tasks like sentiment analysis, machine translation, and text classification.
- Improved Performance in NLP Tasks
Position embedding has shown to improve the performance of neural networks in NLP tasks. For instance, in the case of BERT, a transformer-based architecture that uses position embedding, it has achieved state-of-the-art performance in several NLP tasks such as question-answering, sentiment analysis, and natural language inference.
- Better Generalization
Position embedding helps neural networks to generalize better. It is because the position embedding captures the position of each word in the sentence, making it easier for the neural network to understand the context of the sentence. This way, even if the network encounters a new sentence with different words, it can still make a good prediction because it can rely on the position of the words in the sentence.
- Reduced Overfitting
Position embedding can help reduce overfitting, a common problem in machine learning. Overfitting occurs when the neural network is too complex and learns the training data too well, resulting in poor performance on new data. With position embedding, the neural network can learn the position of each word in the sentence, which helps to reduce overfitting by regularizing the model.
Learned Positional Embeddings
- Hierarchical Perceiver for high-resolution inputs
- learns low-dimensional positional embeddings
- objective function is a masked token prediction
- embeddings are concatenated to input and used as a query for masked prediction
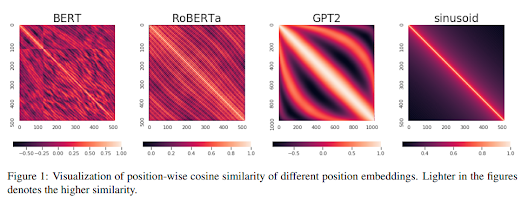
- What Do Position Embeddings Learn?
- sinusoidal embeddings below are not learned
- GPT2 learned positional embeddings as in GPT-1 have a very symmetrical structure
- RoBERTa embeddings mildly similar to sinusoidal
- BERT-trained embeddings, up to position 128, are very similar to sinusoidal, but not elsewhere - likely training artefact.
- sinusoidal and GPT-2 were the best for classification
The figure below the Position embedding of the different Language models.
https://aclanthology.org/2020.emnlp-main.555.pdf
Limitations of Position Embedding
While position embedding has several benefits, it also has some limitations. Here are a few:
- Limited Context
Position embedding only captures the positional information of the words in the sentence. It does not capture the relationship between the words or the context of the sentence. Therefore, it may not be suitable for tasks that require a deeper understanding of the sentence structure.
- Complexity
Position embedding can increase the complexity of the neural network, which can make it more challenging to train and optimize. This can result in longer training times and higher computational costs.
How to Implement Position Embedding in TensorFlow
import tensorflow as tf
class PositionEmbedding(tf.keras.layers.Layer):
def __init__(self, max_length, embedding_dim):
super(PositionEmbedding, self).__init__()
self.max_length = max_length
self.embedding_dim = embedding_dim
def build(self, input_shape):
self.position_embedding = self.add_weight(
shape=(self.max_length, self.embedding_dim),
initializer=tf.keras.initializers.RandomNormal(),
trainable=True
)
def call(self, inputs):
batch_size = tf.shape(inputs)[0]
sequence_length = tf.shape(inputs)[1]
position = tf.tile(
tf.expand_dims(tf.range(self.max_length), 0),
[batch_size, 1]
)[:, :sequence_length]
return inputs + tf.nn.embedding_lookup(self.position_embedding, position)In this implementation, we define a PositionEmbedding class that inherits from 'tf.keras.layers.Layer'. The constructor takes two arguments: 'max_length' and 'embedding_dim', which specify the maximum sequence length and the embedding dimension, respectively.
In the build method, we define the position embedding matrix as a trainable weight tensor with shape (max_length, embedding_dim). We use a RandomNormal initializer to initialize the weights.
In the call method, we first get the batch size and sequence length of the input tensor. We then create a position tensor with shape (batch_size, sequence_length) that contains the position of each element in the input sequence. We use 'tf.range' to create a tensor with values [0, 1, 2, ..., max_length-1], and then use 'tf.tile' to repeat it batch_size times along the first dimension. We finally slice the resulting tensor to keep only the first sequence_length elements.
We then use 'tf.nn.' embedding_lookup to look up the position embeddings for each element in the position tensor. We add the resulting tensor to the input tensor to obtain the final output.
To use this 'PositionEmbedding' layer in a TensorFlow model, you can simply add it as a layer:
model = tf.keras.Sequential([ tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length), PositionEmbedding(max_length, embedding_dim), tf.keras.layers.GlobalAveragePooling1D(), tf.keras.layers.Dense(num_classes, activation='softmax') ])
Here, we first add an Embedding layer to convert each word index to a dense embedding vector. We then add the 'PositionEmbedding' layer to add positional information to the embeddings. We follow it up with a 'GlobalAveragePooling1D' layer to aggregate the embeddings across the sequence length, and finally a Dense layer with a softmax activation to output the class probabilities.
Conclusion
Position embedding is a crucial technique used in NLP to represent the position of words in a sentence along with their meaning. It helps neural networks to create a better representation of sequential data, improve performance in NLP tasks, generalize better, and reduce overfitting. While position embedding has some limitations, its benefits make it an essential technique for NLP tasks.
Comments
Post a Comment