QLoRA is an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance . It backpropagates gradients through a frozen, 4-bit quantized pre-trained language model into Low-Rank Adapters (LoRA). LoRA is the predecessor of QLoRA. It is a low-rank adapter-based approach for efficient finetuning of large language models. LoRA uses a low-rank adapter matrix to project the high-dimensional output of a pre-trained language model to a lower-dimensional space, which is then used as input to a task-specific layer. The authors show that LoRA can be used to finetune large language models with up to 1.3B parameters on a single GPU with minimal loss in performance.
QLoRA builds on LoRA and introduces several innovations to further reduce memory usage and improve performance. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information-theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and paged optimizers to manage memory spikes.
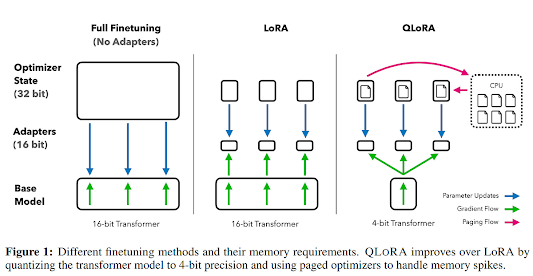
QLoRA has been used to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). The authors present Guanaco, their best model family, which outperforms all previously openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU.
The paper contains several equations and technical notes. However, it does not contain any images. The authors have released all their models and code, including CUDA kernels for 4-bit training.
QLoRA Implementation
To implement QLoRA in Python, you can use the code provided by the authors in their GitHub repository. The repository contains the code for training and finetuning QLoRA on various datasets. The authors have also provided a detailed README file that explains how to use the code and reproduce their results.
You can clone the repository using the following command:
git clone https://github.com/microsoft/QLoRA.git
Once you have cloned the repository, you can navigate to the code directory and run the train.py script to train QLoRA on your dataset. You can also use the finetune.py script to finetune a pre-trained QLoRA model on your task.
The authors have used PyTorch to implement QLoRA. Therefore, you will need to have PyTorch installed on your system before running the code. You can install PyTorch using pip:
pip install torch

Comments
Post a Comment