
In the ever-evolving landscape of machine learning, a new paradigm often emerges that challenges conventional approaches and paves the way for breakthroughs. The Perceiver model is one such paradigm-shifting advancement, pushing the boundaries of image classification through its innovative General Perception with Iterative Attention framework. In this blog post, we'll dive deep into the Perceiver model, unraveling its technical intricacies, and understanding how it redefines image classification.
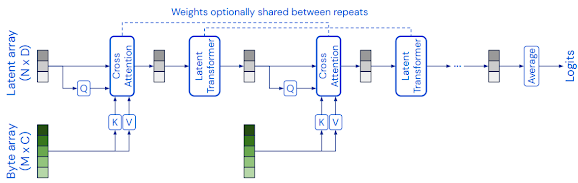
Introduction to the Perceiver Model
The Perceiver model, introduced by DeepMind in their research paper "Perceiver: General Perception with Iterative Attention," presents a novel architecture for handling a wide range of sensory data, particularly focusing on image classification. Unlike traditional convolutional neural networks (CNNs) that rely on fixed-size receptive fields and self-attention mechanisms, the Perceiver model takes a more holistic approach by integrating content-based and position-based attention mechanisms.
Iterative Attention Mechanism
At the core of the Perceiver model lies its Iterative Attention mechanism, which combines two attention types: content-based and position-based attention. This unique blend allows the model to effectively capture both local and global features within the input data.
- Content-Based Attention: This type of attention allows the Perceiver model to selectively focus on relevant parts of the input data. By calculating the similarity between each query vector and the content vectors, the model can identify which parts of the data are most relevant for making predictions.
- Position-Based Attention: To incorporate spatial information, the Perceiver model employs position-based attention. This mechanism enables the model to understand the relative positions and distances between different elements in the input data, facilitating the capture of global context.
Architecture Overview
The Perceiver model's architecture can be broken down into the following key components:
- Encoder: The encoder processes the raw input data and converts it into a set of queries and content vectors. These vectors act as the model's internal representation of the data, allowing it to abstract relevant information.
- Cross-Attention: This is where the content-based and position-based attention mechanisms come into play. The model performs cross-attention between the queries and content vectors, refining its understanding of both local and global features.
- Transformer Layers: The Perceiver model employs a series of transformer layers that iteratively refine the attention mechanism. This iterative process enables the model to progressively capture more complex relationships within the data.
- Decoder: The decoder takes the refined representations from the transformer layers and produces the final predictions. In image classification tasks, these predictions correspond to class labels.
Advantages and Applications
The Perceiver model offers several advantages over traditional approaches to image classification:
Flexibility: The model can handle various data types, making it suitable for multimodal tasks where data comes from different sources.
Scalability: The Iterative Attention mechanism enables the model to scale to larger input sizes without a significant increase in computational complexity.
Global and Local Context: By combining content-based and position-based attention, the Perceiver model can capture both local and global context, leading to more informed predictions.
The applications of the Perceiver model extend beyond image classification. It has shown promising results in tasks such as video classification, language modeling, and even generating images.
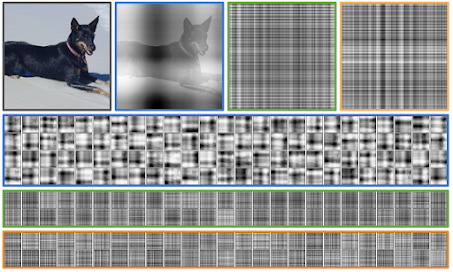
Attention maps from the first, second, and eighth (final) cross-attention layers of a model on ImageNet with 8 cross-attention
modules. Cross-attention modules 2-8 share weights in this model
Source: https://arxiv.org/pdf/2103.03206.pdf
Implementation of the Perceiver Model in TensorFlow
import torch
import torch.nn as nn
import torch.optim as optim
class ContentBasedAttention(nn.Module):
def __init__(self, dim, num_queries, num_content):
super(ContentBasedAttention, self).__init__()
self.dim = dim
self.num_queries = num_queries
self.num_content = num_content
self.to_q = nn.Linear(dim, num_queries)
self.to_v = nn.Linear(dim, num_content)
def forward(self, queries, content):
q = self.to_q(queries) # (batch_size, num_queries, dim)
v = self.to_v(content) # (batch_size, num_content, dim)
# Calculate attention scores
attn_scores = torch.einsum('bqd,bvd->bqv', q, v) # (batch_size, num_queries, num_content)
# Softmax over content dimension
attn_probs = torch.softmax(attn_scores, dim=2) # (batch_size, num_queries, num_content)
# Weighted sum of content vectors
attended_content = torch.einsum('bqv,bvd->bqd', attn_probs, v) # (batch_size, num_queries, dim)
return attended_content
class PositionBasedAttention(nn.Module):
def __init__(self, dim, num_queries, num_positions):
super(PositionBasedAttention, self).__init__()
self.dim = dim
self.num_queries = num_queries
self.num_positions = num_positions
self.to_q = nn.Linear(dim, num_queries)
self.to_r = nn.Linear(dim, num_positions)
def forward(self, queries, positions):
q = self.to_q(queries) # (batch_size, num_queries, dim)
r = self.to_r(positions) # (batch_size, num_positions, dim)
# Calculate attention scores
attn_scores = torch.einsum('bqd,brd->bqr', q, r) # (batch_size, num_queries, num_positions)
# Softmax over positions dimension
attn_probs = torch.softmax(attn_scores, dim=2) # (batch_size, num_queries, num_positions)
# Weighted sum of position vectors
attended_positions = torch.einsum('bqr,brd->bqd', attn_probs, r) # (batch_size, num_queries, dim)
return attended_positions
class PerceiverLayer(nn.Module):
def __init__(self, dim, num_queries, num_content, num_positions):
super(PerceiverLayer, self).__init__()
self.content_attention = ContentBasedAttention(dim, num_queries, num_content)
self.position_attention = PositionBasedAttention(dim, num_queries, num_positions)
# Other components of the layer
def forward(self, input_data):
queries = input_data # Input data is used as queries
content = input_data # Input data is also used as content
positions = torch.arange(input_data.size(1)).unsqueeze(0).repeat(input_data.size(0), 1).float()
attended_content = self.content_attention(queries, content)
attended_positions = self.position_attention(queries, positions)
# Other computations in the layer
return attended_content, attended_positions
class Perceiver(nn.Module):
def __init__(self, input_dim, num_queries, num_content, num_positions, num_layers):
super(Perceiver, self).__init__()
self.layers = nn.ModuleList([
PerceiverLayer(input_dim, num_queries, num_content, num_positions)
for _ in range(num_layers)
])
# Other components of the Perceiver
def forward(self, input_data):
content = input_data
positions = torch.arange(input_data.size(1)).unsqueeze(0).repeat(input_data.size(0), 1).float()
for layer in self.layers:
content, positions = layer(content)
# Other computations in the Perceiver
return content
# Create the Perceiver model
input_dim = 3 # Number of channels in the input image
num_queries = 16
num_content = 256
num_positions = 64
num_layers = 4
perceiver_model = Perceiver(input_dim, num_queries, num_content, num_positions, num_layers)
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(perceiver_model.parameters(), lr=0.001)
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
for batch_idx, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
outputs = perceiver_model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], Batch [{batch_idx+1}/{len(train_loader)}], Loss: {loss.item():.4f}")
print("Training complete!")
# Evaluate the model on the test set
perceiver_model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = perceiver_model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f"Accuracy on the test set: {(100 * correct / total):.2f}%")Conclusion
The Perceiver model represents a significant step forward in image classification by introducing the General Perception with Iterative Attention framework. Its ability to capture both local and global features through the content-based and position-based attention mechanisms opens up new possibilities for understanding complex data. As researchers and practitioners continue to explore and refine the Perceiver model, we can anticipate even more exciting developments in the realm of machine learning and artificial intelligence.
Comments
Post a Comment