
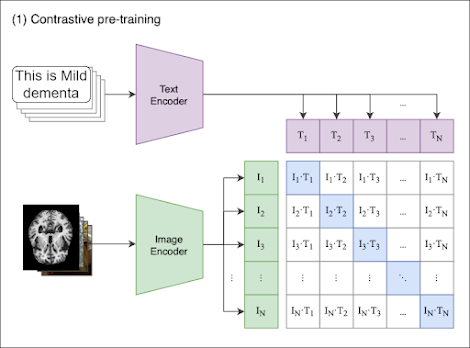
In recent years, the field of artificial intelligence and machine learning has made significant progress, enabling researchers and developers to achieve remarkable results. The CLIP (Contrastive Language-Image Pretraining) model from OpenAI is a revolutionary leap in the AI arena, taking advantage of its multimodal capability to comprehend and interrelate text and images. CLIP presents enormous potential in a multitude of applications, especially zero-shot classification, as discussed in our previous post.
CLIP (Contrastive Language-Image Pretraining)
The CLIP model is a powerful tool that can understand and correlate images and text simultaneously. However, the model’s generalized training on a large corpus of internet text and images might not make it an expert in understanding certain specific or specialized types of images or text. To truly leverage the capabilities of the pre-trained CLIP model for a specific task or domain, fine-tuning is a crucial step.
The following sections of this post will provide you with a step-by-step guide on how to fine-tune the CLIP model with your own custom dataset using Python. The guide will cover the following steps:
- Importing necessary libraries
- Preparing the dataset
- Defining the model
- Defining the optimizer and loss function
- Training the model
- Evaluating the model
FineTuning CLIP for Alzheimer’s disease classification
Here is a step-by-step guide on how to finetune a CLIP model for Alzheimer’s disease classification:
- Data Collection: Collect a dataset of MRI scans of patients with and without Alzheimer’s disease. You can use publicly available datasets such as the Alzheimer’s Disease Neuroimaging Initiative (ADNI) dataset1.
- Data Preprocessing: Preprocess the data by normalizing the pixel values, resizing the images, and splitting the dataset into training and validation sets.
- Model Selection: Choose a pre-trained CLIP model that is suitable for your task. You can use models such as ViT-B/32 or RN501.
- Model Finetuning: Finetune the selected CLIP model on the training dataset using transfer learning. You can use libraries such as PyTorch and Hugging Face Transformers1 to finetune the model.
- Model Evaluation: Evaluate the performance of the finetuned model on the validation dataset. You can use metrics such as accuracy, precision, recall, and F1-score to evaluate the model.
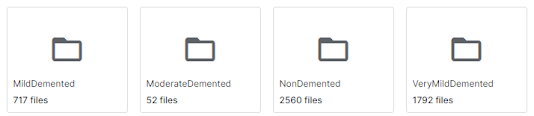
Data Collection
For simplicity, we will use the public dataset for Alzheimer's disease classification available on Kaggle as an example. The data consists of MRI images. The data has four classes of images both in training as well as a testing set:
- Mild Demented
- Moderate Demented
- Non Demented
- Very Mild Demented
as we are using the CLIP model, we of course need image input data and their text descriptions. we will create the text files and save them in text or json files. the description of every image is simple. we will just describe the condition or class of the image. for example, our first image class is Mild Demented, so we will describe it as 'this image is a MiLd Dementa', the second image class will be described as 'this is a Moderate Demented' etc...
Here is an example code snippet that demonstrates how to finetune a CLIP model using PyTorch and Hugging Face Transformers for the task of Alzheimer’s disease prediction:
import torch
import clip
from torch.utils.data import Dataset, DataLoader
# Load the pre-trained CLIP model and tokenizer
model, preprocess = clip.load("ViT-B/32", device="cuda")
# Define the dataset class
class MRIDataset(Dataset):
def __init__(self, data, targets):
self.data = data
self.targets = targets
def __len__(self):
return len(self.data)
def __getitem__(self, index):
image = Image.open(self.data[index])
image = preprocess(image).unsqueeze(0)
text = self.targets[index]
text_tokens = tokenizer(text, return_tensors="pt").input_ids.squeeze(0)
return image, text_tokens
# Prepare the dataset
train_data = ...#load the images and text decription
train_targets = ...#outputs classes
val_data = ...#load the images and text decription
val_targets = ...#outputs classes
train_dataset = MRIDataset(train_data, train_targets)
val_dataset = MRIDataset(val_data, val_targets)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
# Define the model
class CLIPModel(torch.nn.Module):
def __init__(self):
super(CLIPModel, self).__init__()
self.clip = model
self.fc = torch.nn.Linear(512, 2)
def forward(self, x):
x = self.clip.visual(x)
x = x.mean(dim=1)
x = self.fc(x)
return x
model = CLIPModel().cuda()
# Define the optimizer and loss function
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
criterion = torch.nn.CrossEntropyLoss()
# Train the model
for epoch in range(3):
model.train()
for images, targets in train_loader:
images = images.cuda()
targets = targets.cuda()
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, targets in val_loader:
images = images.cuda()
targets = targets.cuda()
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
accuracy = 100 * correct / total
print(f"Epoch {epoch + 1}, Validation Accuracy: {accuracy:.2f}%")
Comments
Post a Comment