
Retrieval Augmented Generation (RAG) is a technique that combines an information retrieval component with a text generator model. RAG can be fine-tuned and its internal knowledge can be modified in an efficient manner and without needing retraining of the entire model.
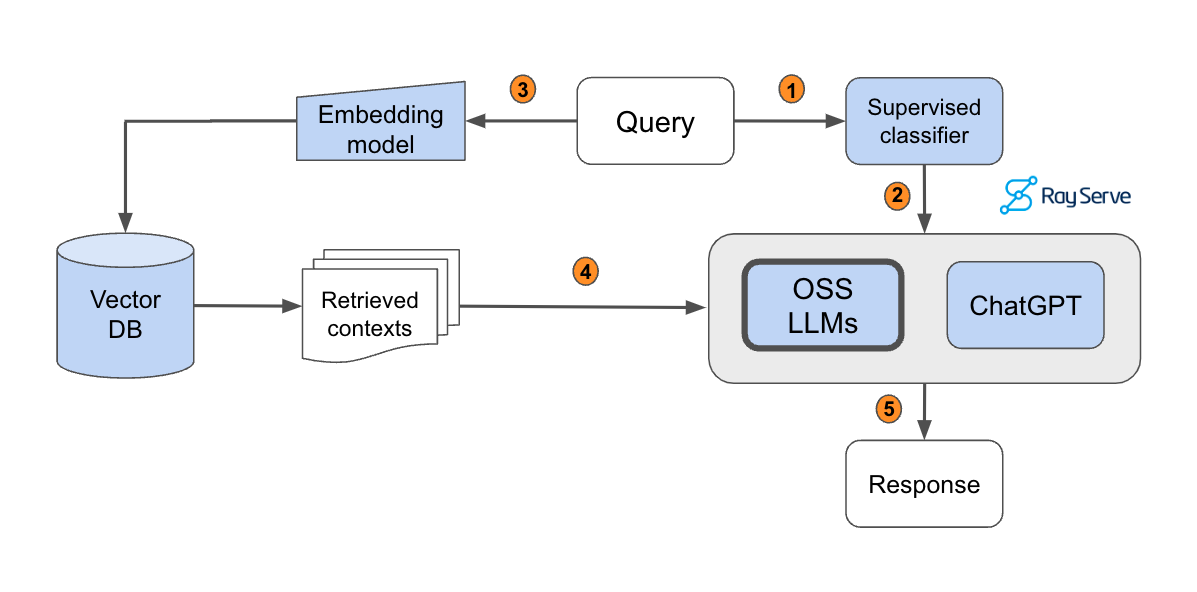
RAG takes an input and retrieves a set of relevant/supporting documents given a source (e.g., Wikipedia). The documents are concatenated as context with the original input prompt and fed to the text generator which produces the final output. RAG is used to improve the quality of generative AI by allowing large language model (LLMs) to access external knowledge to supplement their internal representation of information. RAG provides timeliness, context, and accuracy grounded in evidence to generative AI, going beyond what the LLM itself can provide.
RAG has two phases: retrieval and content generation. In the retrieval phase, algorithms search for and retrieve snippets of information relevant to the user’s prompt or question. In an open-domain, consumer setting, those facts can come from indexed documents on the internet; in a closed-domain, enterprise setting, a narrower set of sources are typically used for added security and reliability. RAG is currently the best-known tool for grounding LLMs on the latest, verifiable information, and lowering the costs of having to constantly retrain and update them
RAG is implemented in LLM-based question answering systems to improve the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information.
RAG techniques can be used to improve the quality of a generative AI system’s responses to prompts, beyond what an LLM alone can deliver. RAG allows language models to bypass retraining, enabling access to the latest information for generating reliable outputs via retrieval-based generation.
In summary, RAG is a technique that combines an information retrieval component with a text generator model to improve the quality of generative AI by allowing LLMs to access external knowledge to supplement their internal representation of information. RAG provides timeliness, context, and accuracy grounded in evidence to generative AI, going beyond what the LLM itself can provide. RAG is implemented in LLM-based question answering systems to improve the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information.
What are Some Illustrations of RAG?
To provide a demonstration of how RAG operates, let's take an example. Imagine you are using a chatbot that utilizes RAG, and you ask it, "Who received the Nobel Prize in Literature in 2023?" The chatbot lacks this data in its pre-trained model since its training data only extends up to 2021.
Nonetheless, due to its RAG capabilities, the chatbot can employ its retrieval component to search its non-parametric memory for the most recent recipients of the Nobel Prize in Literature. Once it locates this information, it can generate a response based on the retrieved documents.
Implementing RAG with a Pre-Trained Model: A Simplified Guide
Here's a streamlined guide on how to integrate RAG on top of an existing LLM:
- Select a pre-trained LLM: Start by choosing a pre-trained LLM as your foundational generative model. Models like GPT-3 or GPT-4 make excellent starting points due to their strong natural language comprehension and generation abilities.
- Data collection: Assemble a substantial collection of data to serve as your knowledge repository. This may encompass text documents, articles, manuals, databases, or any other pertinent information that your RAG model will use for retrieval.
- Develop a retrieval mechanism: Create an efficient retrieval mechanism capable of searching through your knowledge source. This mechanism can utilize techniques like TF-IDF, BM25, dense retrievers such as Dense Passage Retrieval (DPR), or other neural methods. Train or fine-tune the retrieval model using your specific knowledge source to ensure it can effectively locate relevant information.
- Integration: Seamlessly integrate the generative and retrieval components. Typically, the retrieval model selects context from the knowledge source and provides it to the generative model as input. The generative model then combines this context with the user's query to generate a relevant response.
- Fine-tuning: Customize the RAG model for your particular use case. This may involve training the model to perform tasks like question answering, summarization, or content generation using your dataset.
- Scalability and deployment: Ensure that your RAG model is scalable and can accommodate a large user base. Deployment options may include cloud services, on-premises servers, or edge devices, depending on your requirements. Organizations, research institutions, and tech companies are the primary entities incorporating RAG models into applications such as chatbots, virtual assistants, content generation platforms, and more.
- Monitoring and maintenance: Ongoing monitoring is crucial to ensure that the RAG model delivers accurate and current information. Consider collaborating with a reliable partner like Innodata to regularly update the model with fresh data from your knowledge source and retrain it as necessary to maintain its effectiveness.
Comments
Post a Comment