
Vector databases are becoming increasingly popular for building AI-powered applications, including LLM apps. In this tutorial, we will cover the basics of vector databases, how they are used, their benefits, and their implementation in Python for LLM.
What is a Vector Database?
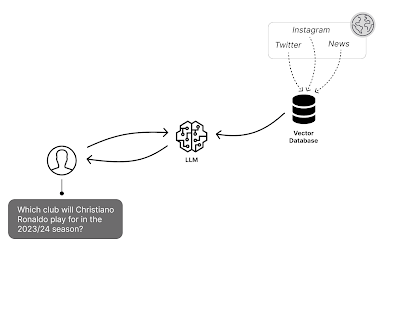
A vector database is a type of database that stores data as numeric vectors in a coordinate space. This allows similarities between vectors to be calculated via operations like cosine similarity. By encoding data as vectors, developers can leverage the mathematical properties of vector spaces to achieve fast similarity search across very large datasets
How are Vector Databases Used?
Vector databases are used to enable fast similarity search and scale across data points. For LLM apps, vector indexes can simplify architecture over full-text search. Developers can build AI-powered applications in Python on vector databases by encoding data as vectors and using them to search for similar data points.
Benefits of Vector Databases
Some benefits of vector databases include:
- Fast similarity search: Vector databases enable fast similarity search across very large datasets.
- Simplified architecture: Vector indexes can simplify architecture over full-text search.
- Efficient comparison: The most up-to-date embedding models are highly capable of understanding the semantics/meaning behind words and translating them into vectors. This allows for efficient comparison of sentences with each other.
Implementation in Python for LLM
Developers can implement vector databases in Python for LLM using standalone Python libraries that implement vector indices, such as FAISS, Pathway LLM, and Annoy, The workflow for implementing vector databases and vector indexes in LLM apps involves:
1. Enriching or cleaning the data. This is a lightweight data transformation step to help with data quality and consistent content formatting. It is also where data may need to be enriched.
2. Encoding data as vectors via models. The models have some transformers included (e.g. sentence transformers).
3. Creating a vector index which enables fast context-based search on the data.
There are two different vector store solutions that developers can use in Python for LLM: Spice, which is a vector library, and Chroma DB, an open-source vector database. Developers can prepare their documents for insertion into PostgreSQL and pgvector using LangChain document transformer TextSplitter. They can also create embeddings from their data using the OpenAI embeddings model and insert them into PostgreSQL and pgvector.
To implement vector databases in Python for LLM, developers can use standalone Python libraries that implement vector indices, such as FAISS, Pathway LLM, and Annoy
1. Additionally, developers can use LangChain and pgvector as a vector database for OpenAI embeddings data
2. Here are the steps to implement vector databases in Python for LLM using pgvector:
- Prepare your documents for insertion into PostgreSQL and pgvector using LangChain document transformer TextSplitter.
- Create embeddings from your data using the OpenAI embeddings model and insert them into PostgreSQL and pgvector.
- Use embeddings retrieved from a vector database to augment LLM generation.
Here is an example of how to create a PGVector:
from pgvector import Column, PGVector from pgvector import Column, PGVector from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String # Create a PostgreSQL engine engine = create_engine('postgresql://user:password@localhost:5432/mydatabase') # Create a metadata object metadata = MetaData() # Create a table with a vector column mytable = Table('mytable', metadata, Column('id', Integer, primary_key=True), Column('vector', Column(PGVector)) ) # Create the table in the database metadata.create_all(engine)
Conclusion
Vector databases are a powerful tool for building AI-powered applications, including LLM apps. By encoding data as vectors, developers can leverage the mathematical properties of vector spaces to achieve fast similarity search across very large datasets. Vector databases offer many benefits, including fast similarity search, simplified architecture, and efficient comparison. Developers can implement vector databases in Python for LLM using standalone Python libraries that implement vector indices, such as FAISS, Pathway LLM, and Annoy.
Comments
Post a Comment