
The CLIP (Contrastive Language-Image Pre-training) model, developed by OpenAI, is a groundbreaking multimodal model that combines knowledge of English-language concepts with semantic knowledge of images. It consists of a text and an image encoder, which encodes textual and visual information into a multimodal embedding space. The model's architecture aims to increase the cosine similarity score of images and associated text pairs. This is achieved through a contrastive objective, which enhances the efficiency of the model by 4x times.
The CLIP model's forward pass involves running the input through the text and image encoder network, normalizing the embedded features, and using them as input to compute the cosine similarity. The resulting cosine similarity is then returned as logits.
CLIP's versatility is evident in its ability to perform tasks such as zero-shot image classification, image generation, abstract task execution for robots, and image captioning. It has also been used for a wide variety of tasks beyond its original use cases, showcasing its adaptability and potential for diverse applications. The model has demonstrated significant flexibility, outperforming the best ImageNet model on various datasets, including tasks such as OCR, geolocalization, and action recognition. However, it has limitations in tasks requiring depth perception, object counting, and distinguishing between similar objects. Despite these limitations, CLIP's zero-shot accuracy in OCR tasks is notable.
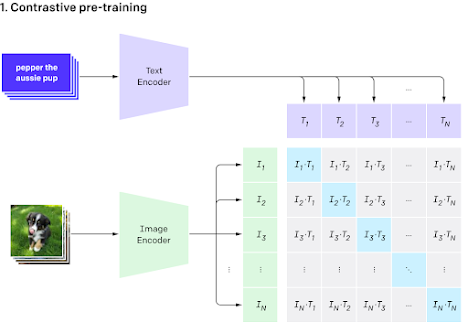
The CLIP model represents a significant advancement in multimodal learning, leveraging both textual and visual information to achieve impressive results across various tasks. Its architecture and contrastive learning approach have positioned it as a versatile and powerful tool for a wide range of applications in computer vision and natural language
Finetuning CLIP Model on Custom Dataset
The process of fine-tuning CLIP models with custom data involves several best practices to ensure effective model adaptation. Here are some key steps and considerations based on the provided search results:
1. Importing Necessary Libraries
The initial part of the script is devoted to importing necessary libraries and modules, including json for handling data, PIL for image processing, and torch
2. Data Preparation
Organize the custom dataset, consisting of images and corresponding textual attributes, in (Image and text) format
3. Model and Library Setup
Import essential libraries, including OpenCV, PyTorch, transformers, and the CLIP model itself
4. Data Loading
Load the input data, including image paths, text descriptions, class labels, and image URLs from JSON files
5. Model Initialization
Initialize the CLIP model and its associated processor, setting the device to either CPU or GPU as available
6. Dataset Creation
Prepare the data for training using a custom dataset class, tokenizing the text descriptions, and preprocessing the images
7. Fine-Tuning Process
The fine-tuning process involves loading the custom dataset and corresponding images, and then training the model using contrastive learning to learn a joint embedding representation of images and captions
By following these best practices, developers can effectively fine-tune CLIP models with custom data to adapt the model to specific tasks or domains. Here is the PyTorch code:
import json
import os
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from transformers import CLIPProcessor, CLIPModel
# Load the input data, including image paths, text descriptions, class labels, and image URLs from JSON files
with open('data.json', 'r') as f:
data = json.load(f)
# Initialize the CLIP model and its associated processor, setting the device to either CPU or GPU as available
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
model.to(device)
processor = CLIPProcessor.from_pretrained('openai/clip-vit-base-patch32')
# Prepare the data for training using a custom dataset class, tokenizing the text descriptions, and preprocessing the images
class CustomDataset(Dataset):
def __init__(self, data, transform=None):
self.data = data
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path = self.data[idx]['image_path']
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
text = self.data[idx]['text']
label = self.data[idx]['label']
input_dict = processor(text=text, images=img, return_tensors='pt', padding=True)
input_dict = {k: v.to(device) for k, v in input_dict.items()}
return input_dict, label
# Fine-tune the model using contrastive learning to learn a joint embedding representation of images and captions
dataset = CustomDataset(data, transform=transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()]))
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
optimizer = optim.Adam(model.parameters(), lr=1e-5)
criterion = nn.CrossEntropyLoss()
for epoch in range(10):
running_loss = 0.0
for i, (inputs, labels) in enumerate(dataloader):
optimizer.zero_grad()
outputs = model(**inputs)
loss = criterion(outputs.logits, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1} loss: {running_loss / len(dataloader)}')This code loads the input data from a JSON file, initializes the CLIP model and its associated processor, prepares the data for training using a custom dataset class, and fine-tunes the model using contrastive learning to learn a joint embedding representation of images and captions. Note that this is just an example, and the specific implementation may vary depending on the use case and data.
Comments
Post a Comment