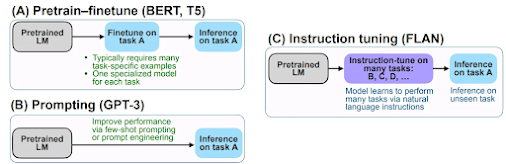
In recent years, the training methodologies for NLP (Natural Language Processing) and ML (Machine Learning) models have undergone several transformations. The introduction of pre-trained models like BERT led to the widespread practice of fine-tuning these pre-trained models for specific tasks downstream. The growing capacity of increasingly larger models subsequently facilitated in-context learning by using prompts. Most recently, a novel approach known as instruction tuning has emerged as the latest technique to make Large Language Models (LLMs) more practical and effective. In this blog post, we will delve into some of the most popular datasets employed for instruction tuning. Subsequent editions will delve into the most up-to-date instruction datasets and models that have been fine-tuned using these instructions.
What is Instruction Tuning?
The primary distinction between instruction tuning and conventional supervised fine-tuning lies in the nature of the training data employed. While supervised fine-tuning train models solely on input examples and their corresponding outputs, instruction tuning enriches the training data by incorporating instructions alongside input-output examples. This augmentation of data equips instruction-tuned models with greater adaptability, facilitating their ability to generalize effectively to new and diverse tasks.
The methodologies for constructing instruction-tuning datasets can vary. Zhang et al. (2023) have provided a comprehensive overview of existing
instruction datasets, which can be broadly categorized into two main types:
- Instructions integrated into existing NLP tasks: In this category, instructions are seamlessly integrated into pre-existing NLP tasks, enhancing the dataset's utility for instruction tuning.
- Utilization of data from category (a) to condition model-generated instruction-input-output tuples: Here, the data from the first category is harnessed to condition models in the generation of novel instruction-input-output tuples.
Now, let's examine some of the most prominent instruction datasets:
1. Natural Instructions (Mishra et al., 2022): This dataset comprises 193,000 instruction-output examples derived from 61 pre-existing English NLP tasks. Instructions have been gathered through crowd-sourcing efforts for each dataset, and they are standardized to conform to a common schema. Consequently, the instructions in this dataset exhibit a more structured format compared to other datasets. However, it's worth noting that the outputs in this dataset tend to be relatively concise, which may limit its applicability for generating longer, more extensive content.
2. Natural Instructions v2 / Super-Natural Instructions (Wang et al., 2022): This dataset represents a significant expansion and enhancement of the Natural Instructions dataset. It is the result of crowd-sourced efforts and encompasses instruction data derived from both existing NLP tasks and straightforward synthetic tasks. Remarkably, it comprises a substantial collection of 5 million examples spanning 76 tasks and encompassing 55 different languages.
Compared to the earlier Natural Instructions dataset, Natural Instructions v2 / Super-Natural Instructions takes a more simplified approach. Instructions in this dataset are structured to include a task definition along with positive and negative examples, accompanied by explanatory context. This added context and structure provide valuable insights for instruction-tuning models, enhancing their ability to comprehend and apply instructions effectively across various tasks and languages.

3. Unnatural Instructions (Honovich et al., 2023): This dataset represents an intriguing development in the realm of instruction-based data collection. It comprises approximately 240,000 examples that were automatically generated. The dataset's creation process involves prompting the InstructGPT model (text-davinci-002) with three instances of Super-Natural Instructions, each consisting of an instruction, an input, and potential output constraints. The model is then instructed to generate a new example based on these inputs. Importantly, the output generation is performed separately, taking into account the generated instruction, input, and constraints. What sets Unnatural Instructions apart from its predecessor, Super-Natural Instructions, is its broader scope and diversity of tasks. While many examples within the dataset still pertain to classical NLP tasks, it also incorporates instances of other intriguing and varied tasks, thereby expanding the dataset's applicability and utility for instruction-tuning models.

4. Self-Instruct (Wang et al., 2023): Self-Instruct is another intriguing dataset that bears similarities to Unnatural Instructions. It encompasses a total of 82,000 examples, which were automatically generated through the utilization of the InstructGPT model. This dataset is unique in its methodology, as it decouples the example generation process into distinct steps. In the Self-Instruct dataset, the generation process proceeds as follows:
- Instruction Generation: Initially, the dataset creators generate instructions.
- Input Generation: Subsequently, the input is generated, taking into account the previously generated instruction.
- Output Generation: Finally, the output is generated, with the input and instruction serving as conditioning factors.
For classification tasks, the authors employ a specific strategy to mitigate bias. They first generate potential output labels and then condition the input generation on each class label separately, thus avoiding any undue bias towards a particular label.
It is important to note that while the generated instructions in the Self-Instruct dataset are predominantly valid, the generated outputs often exhibit a degree of noise, reflecting the complexities and challenges associated with automatic example generation.

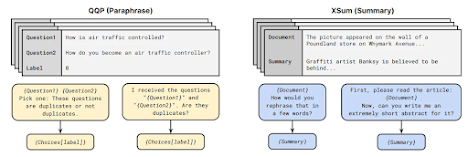
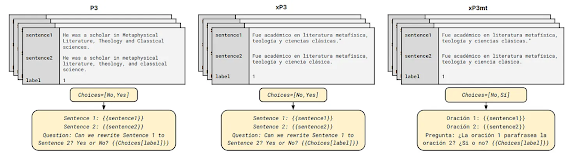
5. P3 (Public Pool of Prompts; Sanh et al., 2022): P3 represents a valuable resource in the field of NLP and instruction-based data collection. It is a crowd-sourced compilation of prompts designed for a comprehensive set of 177 English NLP tasks. Notably, for each dataset, an average of approximately 11 different prompts is made available. This multiplicity of prompts offers researchers the opportunity to explore and analyze the influence and effects of various prompt formulations on model performance and behavior. In contrast to the instructions found in the aforementioned instruction datasets, P3 prompts tend to be more concise and less elaborate. This distinction in prompt style provides researchers with a diverse range of inputs to assess how different prompt formats impact the outcomes of NLP models and their performance on specific tasks.
6. xP3, xP3mt (
Muennighoff et al., 2023): An extension of P3 including 19 multilingual datasets and 11 code datasets, with English prompts. They also release a machine-translated version of the data (xP3mt), which contains prompts automatically translated into 20 languages. Fine-tuning on multilingual tasks with English prompts further improves performance beyond only fine-tuning on English instruction data.
7. Flan 2021 / Muffin (Wei et al., 2022): Flan 2021, sometimes referred to as Muffin, is a notable resource in the realm of NLP. This dataset comprises a collection of prompts created for 62 different English text datasets. Each of these datasets is accompanied by 10 distinct prompt templates, offering a variety of input formulations for researchers and practitioners to explore. For classification tasks within Flan 2021 / Muffin, an interesting addition is the inclusion of an "OPTIONS" suffix appended to the input. This suffix serves the purpose of indicating output constraints, allowing for more specific and controlled interactions with the model. This feature can be particularly valuable when dealing with classification tasks where precise control over the model's responses is essential.
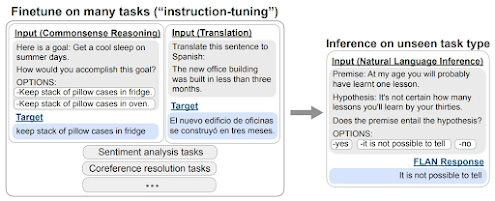
8. Flan 2022 (Chung et al., 2022): Flan 2022 represents a comprehensive and amalgamated dataset that draws from various existing sources, including Flan 2021, P3, Super-Natural Instructions, alongside the incorporation of supplementary datasets related to reasoning, dialogue, and program synthesis. This diverse compilation enriches the dataset landscape, providing an extensive set of resources for NLP research and experimentation. Of notable interest within Flan 2022 are the nine newly introduced reasoning datasets, which have received additional annotations in the form of chain-of-thought (CoT) annotations. These CoT annotations, introduced by Wei et al. in 2022, offer a valuable layer of insight into the reasoning processes employed by models when addressing specific tasks. Consequently, Flan 2022 not only encompasses a wide array of data sources but also offers a deeper understanding of the model's thought processes in the context of reasoning tasks. This holistic dataset serves as a valuable resource for advancing the capabilities of NLP models in diverse and challenging tasks.
9. Opt-IML Bench (Iyer et al., 2022): The Opt-IML Bench is an extensive and multifaceted dataset that amalgamates components from various sources, including Super-Natural Instructions, P3, and Flan 2021. In addition to these foundational elements, this dataset incorporates several other dataset collections that expand its utility and applicability across various NLP research domains. Some noteworthy additions to the Opt-IML Bench include dataset collections pertaining to cross-task transfer, knowledge grounding, dialogue, and an increased number of chain-of-thought datasets. These augmentations extend the scope of tasks and challenges that the dataset can address, making it a versatile resource for evaluating and advancing the capabilities of NLP models across a wide spectrum of tasks, including those requiring cross-task transfer, grounding in knowledge, dialog-based interactions, and intricate reasoning processes. The Opt-IML Bench represents a valuable asset for NLP researchers seeking to explore the limits of model performance and generalization across diverse tasks and domains.
Summary
In recent years, the field of Natural Language Processing (NLP) has witnessed a remarkable surge in the development of instruction-based datasets. These datasets play a pivotal role in training and fine-tuning NLP models for various tasks. In this comprehensive blog post, we delve into the world of instruction-based datasets, exploring some of the most prominent ones that have emerged in recent times.
- Evolution of NLP Training: The blog post begins by discussing the evolution of NLP model training methodologies. It highlights the transition from traditional supervised fine-tuning to the advent of pre-trained models like BERT and the subsequent rise of instruction-based fine-tuning methods.
- Types of Instruction-Based Datasets: The post categorizes instruction-based datasets into several types. It covers datasets where instructions are added to existing NLP tasks, data used to condition models to generate new instruction-input-output tuples, and even datasets automatically generated by models like InstructGPT.
- Introducing Notable Datasets: The blog post introduces readers to several noteworthy instruction-based datasets, such as "Natural Instructions v2 / Super-Natural Instructions," "Unnatural Instructions," "Self-Instruct," "P3 (Public Pool of Prompts)," "Flan 2021 / Muffin," and "Flan 2022." It provides insights into the unique features, sizes, and applications of these datasets.
- Specialized Additions: Some datasets, like "Flan 2021 / Muffin," offer specific features like appending an "OPTIONS" suffix for classification tasks, allowing for greater control over model outputs.
- Enhanced Annotations: The blog post highlights datasets that include valuable annotations, such as chain-of-thought (CoT) annotations, which shed light on the reasoning processes employed by models.
- Opt-IML Bench: The blog post concludes by introducing the "Opt-IML Bench," a comprehensive dataset that amalgamates elements from various sources. This versatile dataset includes collections related to cross-task transfer, knowledge grounding, dialogue, and a larger number of chain-of-thought datasets, making it a robust resource for diverse NLP research endeavors.
In the rapidly evolving landscape of NLP, instruction-based datasets have become invaluable tools for training and evaluating models across a wide range of tasks. By exploring these datasets and understanding their unique features, researchers and practitioners can unlock the potential of NLP models, advancing the field and enabling more accurate, context-aware, and adaptable language understanding and generation.



Comments
Post a Comment