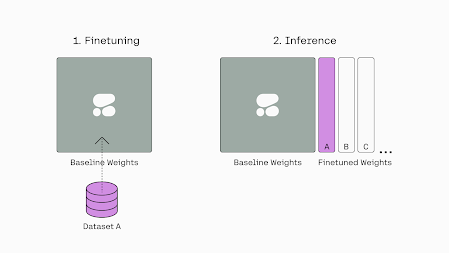
The demand for applications powered by large language models (LLMs) is increasing, from chatbots to virtual assistants to content generation. However, to achieve optimal performance and accuracy, it is necessary to fine-tune these models on specific tasks and domains. Traditionally, finetuning involved updating the weights of all layers in the model, which can be time-consuming and require extensive computational resources. T-Few finetuning is an additive Parameter Efficient Finetuning technique that inserts additional layers, comprising approximately 0.01% of the baseline model's size. It adds 1D vectors L_K, L_V, and L_FF that are multiplied with the K, V, and feed-forward weights during inference. Overview of T-Few Finetuning
T-Few finetuning is an additive Parameter Efficient Finetuning technique that inserts additional layers, comprising approximately 0.01% of the baseline model's size. Specifically, it adds 1D vectors L_K, L_V, and L_FF that are multiplied with the K, V, and feed-forward weights during inference.
T-Few finetuning adds 1D vectors that are multiplied with the K, V, and feed-forward weights during inference. (Source: Liu et. al, 2022)The dimensionality of the T-Few vectors is fixed and determined by the outer dimensions of the K, V, and feed-forward weights in each layer. This means that the dimensionality of the additive weights is fixed, and these weights are generally much smaller than when using adapters. During the finetuning process, the weight updates are localized to the T-Few layers. This isolation of weight updates to the T-Few layers significantly reduces the overall training time compared to updating all layers. This process also reduces the resource footprint required to finetune the model. The T-Few finetuning technique uses an additive Parameter Efficient Finetuning technique that inserts additional layers, comprising approximately 0.01% of the baseline model's size. These additional layers add 1D vectors L_K, L_V, and L_FF that are multiplied with the K, V, and feed-forward weights during inference.
The T-Few finetuning technique is different from traditional finetuning methods because it selectively updates only a fraction of the model's weights, thus reducing training time and computational resources. The T-Few finetuning technique is useful for creating custom LLMs, and it can be used as part of a deep learning model where the embedding is learned along with the model itself. The T-Few finetuning technique is also useful for loading a pre-trained word embedding model, a type of transfer learning.
Finetuning takes a dataset and updates the T-Few weights, which are then utilized during inference (https://txt.cohere.com/tfew-finetuning/).
Stacking T-Few Finetunes
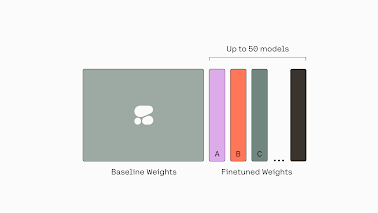
The T-Few finetuning technique allows for efficient serving of multiple finetunes on a single GPU, enhancing serving scalability. By stacking multiple specialized sets of weights to a single base model, we can efficiently serve many finetunes on a single GPU.
https://txt.cohere.com/tfew-finetuning/
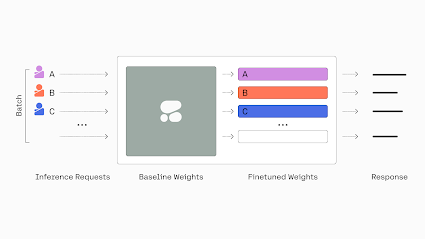
When we stack multiple T-Few finetunes, we now have 2D vectors for L_K, L_V, and L_FFN, where the additional dimension comes from the number of stacked T-Few finetunes. In this case, when we get requests for finetune A and finetune B, we slice the 2D vector into a 1D vector and use this for the computation. We use a unique identifier for each finetune to allow batches to include requests for multiple finetunes. Only the weights corresponding to the finetune requested are used, and we use the conditional computation above to ensure the right set of finetuning weights are used. This approach isolates the output from requests to a specific finetune from the values of the remaining finetune weights in the stack. This isolation in the stacked model serving is important when serving customers with different use cases and ensuring one customer's dataset/request does not negatively or positively impact the other customer's results.
The T-Few stacking approach unlocks the ability to batch requests for different finetunes and perform concurrent inference. Rather than allocating and managing individual GPU resources per finetune, the stacked model condenses many finetunes into a single deployable unit. This maximizes GPU utilization by allowing multiple finetunes to share GPU resources during inference. The concurrent inference capability provided by T-Few stacking revolutionizes the scalability of serving multiple finetunes, making it an ideal approach for applications requiring efficient and high-performance language models.
explains how the low overhead of T-Few's algorithm allows us to optimize how we serve finetunes.
discusses efficient fine-tuning for Llama-7b on a single GPU. Fine-tuning large pre-trained models is an effective transfer mechanism in NLP.
https://txt.cohere.com/tfew-finetuning/
T-Few finetuning is a complex technique for creating custom LLMs. Here are some general steps to implement T-Few finetuning in Python:
- 1. Install the necessary libraries: To implement T-Few finetuning, you will need to install libraries such as TensorFlow, PyTorch, or Hugging Face Transformers. You can install these libraries using pip or conda.
- 2. Load the pre-trained model: You can load a pre-trained model using the library's built-in functions or by using a pre-trained model from the Hugging Face model hub.
- 3. Fine-tune the model: To fine-tune the model, you will need to define the task-specific dataset and the hyperparameters for the training process. You can use the T-Few finetuning technique to selectively update only a fraction of the model's weights, reducing training time and computational resources.
- 4. Evaluate the model: After fine-tuning the model, you will need to evaluate its performance on a validation dataset. You can use metrics such as accuracy, precision, recall, and F1 score to evaluate the model's performance.
- 5. Deploy the model: Once you have fine-tuned and evaluated the model, you can deploy it for use in your application. You can use libraries such as Flask or FastAPI to create a REST API for your model.
- Overall, implementing T-Few finetuning in Python requires a deep understanding of the underlying techniques and tools. It is recommended to follow tutorials and examples provided by the libraries to ensure proper implementation.
Wrap-Up
T-Few finetuning is an efficient approach to finetuning large language models, addressing the challenges of slow training times and costly serving resources. By updating only a small fraction of the model's weights and enabling model stacking, T-Few finetuning significantly reduces training time while maintaining high-quality finetunes. T-Few stacking allows for the concurrent inference of multiple finetunes, maximizing GPU utilization and improving serving scalability. With these benefits, T-Few finetuning becomes a valuable technique for efficient language model development and deployment. The development of LLMs has led to a paradigm shift in natural language processing, greatly improving the performance of various NLP tasks. Training Large Language Models is a complex process that requires meticulous attention to detail and a deep understanding of the underlying techniques. By carefully selecting and curating data, choosing the appropriate model architecture, optimizing the training process, and evaluating performance using relevant metrics and benchmarks, researchers and developers can continuously refine and enhance the capabilities of LLMs. The future of Large Language Models promises exciting advancements and research.


Comments
Post a Comment