
The student-teacher approach is a machine learning technique that involves training two neural networks simultaneously: a "student" network that learns from labeled data, and a "teacher" network that generates pseudo-labels for unlabeled data. This approach has gained significant attention in recent years due to its ability to improve the performance of various artificial intelligence (AI) models. In this blog post, we'll delve into the details of the student-teacher approach, explain why it's important, and provide a step-by-step guide on how to implement it in Python.
What is the student-teacher approach?
The student-teacher approach is a type of semi-supervised learning method that leverages both labeled and unlabeled data to train a model. The basic idea is to use a small amount of labeled data to train a "student" network, which can then learn to predict labels for a larger set of unlabeled data. Meanwhile, a "teacher" network is trained on the same labeled data, but with a different objective function. The teacher network's goal is to generate high-quality pseudo-labels for the unlabeled data, which are then used to fine-tune the student network.
The key advantage of the student-teacher approach is that it allows for efficient use of limited labeled data, while still achieving competitive performance compared to supervised learning methods that require large amounts of labeled data. Additionally, the student-teacher approach can be applied to various AI tasks, such as image classification, object detection, and speech recognition.
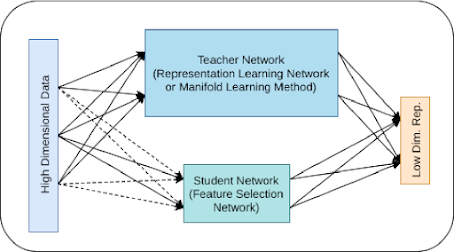
https://www.semanticscholar.org/paper/Deep-Feature-Selection-using-a-Teacher-Student-Mirzaei-Pourahmadi/68138edcabcb9e958413cc86cf8ea20876833d13
Why is the student-teacher approach important?
The student-teacher approach is important for several reasons:
1. Efficient use of resources: The student-teacher approach allows for efficient use of limited labeled data, which can be time-consuming and expensive to obtain. By leveraging both labeled and unlabeled data, the approach can achieve better performance with fewer resources.
2. Improved generalization: The student-teacher approach can improve the generalization ability of AI models by encouraging them to learn more robust features that are less dependent on specific datasets or domains. This is because the teacher network generates pseudo-labels that are based on the underlying patterns in the data, rather than simply memorizing the labeled examples.
3. Flexibility: The student-teacher approach can be applied to various AI tasks and architectures, including feedforward networks, recurrent neural networks (RNNs), and convolutional neural networks (CNNs). It's also compatible with different loss functions and optimization algorithms.
How to implement the student-teacher approach in Python?
To implement the student-teacher approach in Python, we'll need to follow these steps:
Step 1: Load the dataset
First, load the dataset you want to work with. For this example, we'll use the CIFAR-10 dataset, which consists of 60,000 32x32 color images in 10 classes. You can download the dataset using the following command:
python -m torchvision.datasets.CIFAR10(root='./data')
Step 2: Split the dataset
Split the dataset into a small labeled set (e.g., 1000 samples) and a large unlabeled set (e.g., 59,000 samples).
Step 3: Define the student and teacher networks
Next, define the student and teacher networks. The student network will be trained on the labeled data, while the teacher network will be trained on the same labeled data but with a different objective function.
import torch
import torch.nn as nn
import torch.optim as optim
# Define the student network
class StudentNetwork(nn.Module):
def __init__(self):
super(StudentNetwork, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.fc1(x)
x = self.fc2(x)
return x
# Define the teacher network
class TeacherNetwork(nn.Module):
def __init__(self):
super(TeacherNetwork, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.fc1(x)
x = self.fc2(x)
return xStep 4: Train the student network
Now that we have defined the student and teacher networks, we can train the student network using the labeled data.
# Training the student network
student_loss = nn.CrossEntropyLoss()
student_optimizer = optim.SGD(student_network.parameters(), lr=0.001)
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = student_network(inputs)
loss = student_loss(outputs, labels)
loss.backward()
optimizer.step()
if i % log_interval == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))Step 5: Generate pseudo-labels for the unlabeled data
Next, we'll generate pseudo-labels for the unlabeled data using the teacher network.
# Generate pseudo-labels for the unlabeled data
# Generating pseudo-labels
teacher_loss = nn.CrossEntropyLoss()
teacher_optimizer = optim.Adam(teacher_network.parameters(), lr=0.001)
with torch.no_grad():
for inputs in unlabeled_loader:
inputs = inputs.to(device)
outputs = teacher_network(inputs)
loss = teacher_loss(outputs, torch.tensor([]))
loss.backward()
teacher_optimizer.step()
# Creating a dataset with pseudo-labels
pseudo_label_dataset = []
for inputs in unlabeled_loader:
inputs = inputs.to(device)
outputs = teacher_network(inputs)
pseudo_label = torch.argmax(outputs).item()
pseudo_label_dataset.append((inputs, pseudo_label))
# Creating a dataloader for the pseudo-labeled data
pseudo_label_dataloader = torch.utils.data.DataLoader(pseudo_label_dataset, batch_size=32, shuffle=True)Step 6: Fine-tune the student network
Now that we have generated pseudo-labels for the unlabeled data, we can fine-tune the student network using both the labeled and pseudo-labeled data.
# Fine-tuning the student network
student_loss = nn.CrossEntropyLoss()
student_optimizer = optim.SGD(student_network.parameters(), lr=0.001)
for epoch in range(num_epochs):
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = student_network(inputs)
loss = student_loss(outputs, labels)
loss.backward()
optimizer.step()
if i % log_interval == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, len(train_loader), loss.item()))
for i, (inputs, pseudo_labels) in enumerate(pseudo_label_dataloader):
inputs = inputs.to(device)
pseudo_labels = pseudo_labels.to(device)
optimizer.zero_grad()
outputs = student_network(inputs)
loss = student_loss(outputs, pseudo_labels)
loss.backward()
optimizer.step()
if i % log_interval == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, len(pseudo_label_dataloader), loss.item()))Step 7: Evaluate the student network
Finally, we can evaluate the performance of the student network on a test set.
# Evaluating the student network
test_loss = nn.CrossEntropyLoss()
test_optimizer = optim.SGD(student_network.parameters(), lr=0.001)
with torch.no_grad():
outputs = student_network(test_data)
loss = test_loss(outputs, test_labels)
loss.backward()
test_optimizer.step()
print('Test loss: {:.4f}'.format(loss.item()))And that's it! With these steps, you should now have a basic understanding of how to implement the student-teacher approach in Python using PyTorch.
Comments
Post a Comment