
The advancement of AI technology relies heavily on the research community's access to generative AI tools, such as language models. However, the current state of AI models is often restricted by proprietary walls, hindering the progress of innovation. To address this issue, Meta has released LLaMA 2, which aims to democratize access to these powerful tools for researchers and commercial users across the globe. In this post, we will discuss LLaMA models and their latest version; LLaMA 2. Note that this is just an introduction, in later posts, we will explore more advanced topics such as how to fine-tune LLaMA 2 and deploy them into production. Stay tuned.

What is LLaMa!
In February 2023, Meta introduced a project known as LLaMA, which stands for Large Language Model Meta Artificial Intelligence. This extensive language model (LLM) has undergone training across a range of model sizes, spanning from 7 billion to 65 billion parameters. The variations in LLaMa models are attributed to differences in parameter sizes:
- A model with 7 billion parameters, trained on 1 trillion tokens.
- A model with 13 billion parameters.
- A model with 33 billion parameters, trained on 1.4 trillion tokens.
- A model with 65 billion parameters, also trained on 1.4 trillion tokens.
Meta AI has characterized LLaMa as a smaller language model, which holds advantages in terms of adaptability for retraining and fine-tuning. This adaptability is particularly beneficial for commercial enterprises and specialized applications.
Unlike many other potent large language models, which are typically accessible through restricted APIs, Meta AI has chosen to grant access to LLaMa's model weights to the broader AI research community under a noncommercial license. Initially, access was provided selectively to academic researchers, individuals associated with government institutions, civil society organizations, and academic institutions worldwide.
How Was LLaMa Trained?
Similar to the training process of other large language models, LLaMA operates by taking a sequence of words as input and generating subsequent text through iterative prediction.
The training of this language model prioritized text from the top 20 languages with the highest number of speakers, with a particular focus on languages employing Latin and Cyrillic scripts.
The training data for Meta LLaMa primarily originates from extensive public sources, including:
- Webpages gathered by CommonCrawl.
- Open-source code repositories from GitHub.
- Wikipedia articles in 20 different languages.
- Public domain books available through Project Gutenberg.
- The LaTeX source code for scientific papers submitted to ArXiv.
- Questions and answers extracted from Stack Exchange websites.
How Does LLaMa Compare to Other Large Language Models?
According to the developers of LLaMa, their model with 13 billion parameters surpasses GPT-3, which boasts 175 billion parameters, across most Natural Language Processing (NLP) benchmarks. Furthermore, their largest LLaMa model competes effectively with top-tier models such as PaLM and Chinchilla.
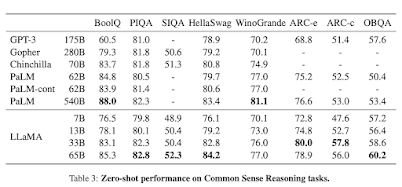
Source: Meta LLaMa vs other LLMs on a reasoning task (Source: LLaMa research paper)
Truthfulness and Bias
In the evaluation of both LLMs, Meta LLaMa demonstrates superior performance in the truthfulness test when compared to GPT-3. However, it is important to note that the results indicate that there is room for improvement in the aspect of truthfulness for LLMs in general. Notably, even though LLaMa with 65 billion parameters is a substantial model, it generates prompts with fewer biases in comparison to other large LLMs, such as GPT-3.
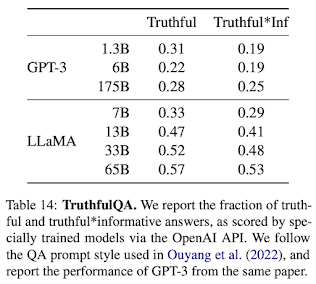
Source: Meta LLaMa vs other LLMs on a reasoning task (Source: LLaMa research paper)
Source: Meta LLaMa vs other LLMs on a reasoning task (Source: LLaMa research paper)
What is LLaMa 2?
LLaMa 2 represents a significant development in the field of large language models. On July 18, 2023, both Meta and Microsoft jointly unveiled their support for the LLaMa 2 family of large language models, which are to be integrated into the Azure and Windows platforms. This collaborative effort underscores the shared commitment of both Meta and Microsoft to democratizing AI and ensuring widespread accessibility to AI models. Notably, Meta has adopted an open approach with LLaMa 2, marking the first time that this model is made available for both research and commercial utilization.
LLaMa 2 has been designed with the primary goal of assisting developers and organizations in the creation of generative AI tools and experiences. It empowers developers with the flexibility to choose the types of models they wish to develop, endorsing the development of both open and cutting-edge models.
As for who can leverage LLaMa 2, customers using Microsoft's Azure platform have the capability to fine-tune and utilize the 7-billion, 13-billion, and 70-billion-parameter versions of the LLaMa 2 models. Additionally, LLaMa 2 is accessible through other providers such as Amazon Web Services and Hugging Face.
For developers operating within the Windows environment, Meta LLaMa 2 has been optimized to function efficiently. Those working with Windows can employ LLaMa 2 by directing it to the DirectML execution provider through the ONNX Runtime. This integration enhances the accessibility of LLaMa 2 for a broader range of developers and users.
References
“Introducing LLaMA: A foundational, 65-billion-parameter language model.” Meta AI, 24 February 2023, https://ai.facebook.com/blog/large-language-model-llama-meta-ai/. Accessed 24 July 2023.
“LLaMA.” Wikipedia, https://en.wikipedia.org/wiki/LLaMA. Accessed 24 July 2023.
“LLaMA: Open and Efficient Foundation Language Models.” arXiv, 13 June 2023, https://arxiv.org/pdf/2302.13971.pdf. Accessed 24 July 2023.
“Microsoft and Meta expand their AI partnership with LLama 2 on Azure and Windows - The Official Microsoft Blog.” The Official Microsoft Blog, 18 July 2023, https://blogs.microsoft.com/blog/2023/07/18/microsoft-and-meta-expand-their-ai-partnership-with-llama-2-on-azure-and-windows/. Accessed 24 July 2023.
“Meta and Microsoft Introduce the Next Generation of Llama.” Meta AI, 18 July 2023, https://ai.meta.com/blog/llama-2/. Accessed 24 July 2023.
Comments
Post a Comment