
The realm of Artificial Intelligence (AI) is no stranger to awe-inspiring advancements, one of which is the development of Large Language Models (LLMs) like GPT-3 and LLama-2. These models have showcased remarkable capabilities in generating human-like text and aiding various natural language processing tasks. However, as with any advancement, challenges arise. One significant challenge that LLMs face is "catastrophic forgetting."
{kind=link}
Generated by AI
What is Catastrophic Forgetting?
Imagine your brain as a constantly evolving repository of knowledge. Now picture learning a new skill or topic so intensely that it erases or distorts your understanding of previously acquired knowledge. This phenomenon is akin to what LLMs experience as catastrophic forgetting. In machine learning, it refers to the unsettling tendency of a model to forget previously learned information when training on new data or tasks.
Catastrophic forgetting occurs due to the nature of the optimization process during training. When a model trains to minimize the current task's loss, it adjusts its parameters to better fit the new data. However, this adjustment often results in the model deviating from its original state, leading to a loss of knowledge encoded in its weights.
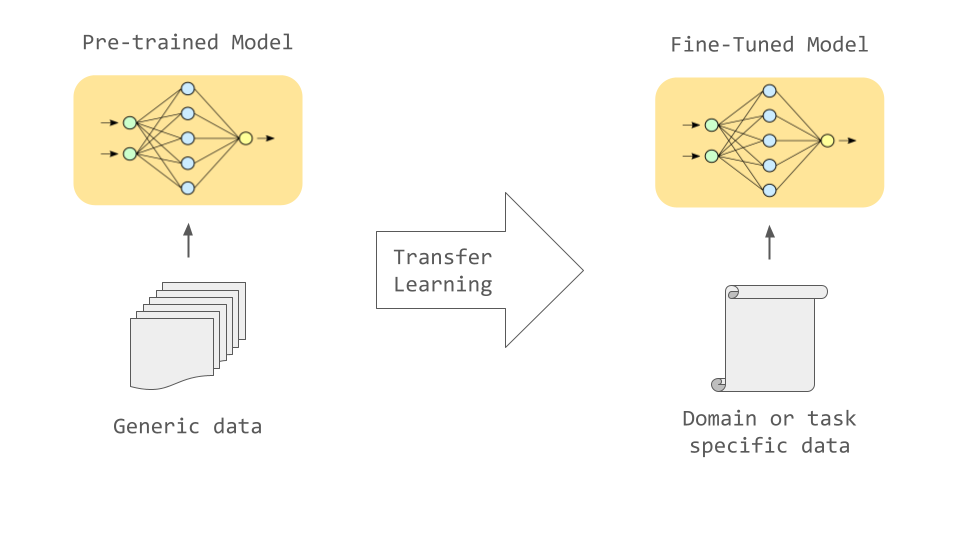
Source: https://www.fuzzylabs.ai/blog-post/llm-fine-tuning-old-school-new-school-and-everything-in-between
Why Does Catastrophic Forgetting Happen?
To understand why catastrophic forgetting happens, we must delve into the intricacies of neural network training. Neural networks, including LLMs, consist of numerous interconnected weights that define their behavior. Training involves adjusting these weights to minimize a loss function, and aligning the model's predictions with the ground truth.
When a model is initially trained on a task, its weights are fine-tuned to capture relevant patterns in the data. However, when we introduce new data or tasks, the model is required to adjust its weights again. This new adjustment, if not managed carefully, can lead to the erosion of patterns learned during previous tasks.
Examples of Catastrophic Forgetting
Let's consider an illustrative example involving a language model trained to translate English and French sentences. During initial training, the model learns translation patterns for both languages. If the model then undergoes fine-tuning on a new task, like summarization, it might inadvertently overwrite some of its language translation knowledge. As a result, the model's translation quality might degrade after fine-tuning.
Strategies to Mitigate Catastrophic Forgetting
Researchers have developed several strategies to tackle catastrophic forgetting in LLMs:
- Regularization: Incorporate regularization techniques like weight decay or dropout during training. These techniques discourage the model from over-adapting to new tasks and help it retain more of its original knowledge.
- Elastic Weight Consolidation (EWC): Assign penalties to important weights learned during earlier tasks. This encourages the model to protect these weights during subsequent training, preventing drastic changes.
- Knowledge Distillation: Transfer knowledge from an older, well-performing model to a newer model. This process minimizes forgetting by passing on insights learned previously.
- Progressive Learning: Gradually introduce new tasks to the model while ensuring that it maintains its performance on older tasks. This gradual exposure helps retain knowledge.
- Multi-Task Training: Train the model on a variety of tasks simultaneously. This approach encourages the model to generalize across tasks, making it less prone to overfitting.
- Adaptive Learning Rates: Implement learning rate strategies that prioritize maintaining performance on older tasks during fine-tuning.
- Continual Learning: Continual learning methods involve training the model incrementally on new tasks while carefully managing the impact on earlier knowledge.
Summary
Catastrophic forgetting poses a unique challenge in the evolution of Large Language Models. As these models grow in complexity and importance, addressing this issue becomes pivotal to maintaining their overall capabilities. By understanding the underlying reasons for catastrophic forgetting and embracing effective mitigation strategies, the AI community is better equipped to usher in a new era of resilient, adaptable, and continuously improving language models.
In the fast-paced world of AI, staying ahead requires not only technical prowess but also a profound understanding of the challenges that come with innovation. Catastrophic forgetting is one such challenge, a puzzle that researchers and practitioners are tirelessly working to solve. As we navigate the future of AI, we remain poised to transform these obstacles into stepping stones toward even greater achievements.
Comments
Post a Comment