
In the realm of artificial intelligence, large language models have emerged as a groundbreaking technology that has transformed the way we interact with computers and machines. These models, driven by sophisticated architectures like Transformers, have revolutionized natural language processing tasks, enabling machines to understand, generate, and manipulate human language in unprecedented ways. In this comprehensive guide, we will delve into the architecture, history, state-of-the-art models, applications, and implementation aspects of large language models, with a special focus on the technical features of Transformers-based architectures.
Understanding Large Language Models
Large language models, often referred to as LLMs, are advanced machine learning models that excel in understanding, generating, and processing human language. These models are designed to handle the complexities of language, including semantics, syntax, context, and even nuances. By training on vast amounts of text data, LLMs learn patterns and structures inherent in language, allowing them to perform tasks like text generation, translation, summarization, sentiment analysis, and more.
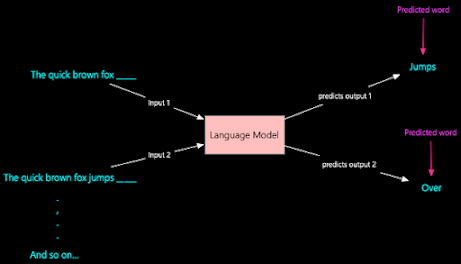
Architecture: The Power of Transformers
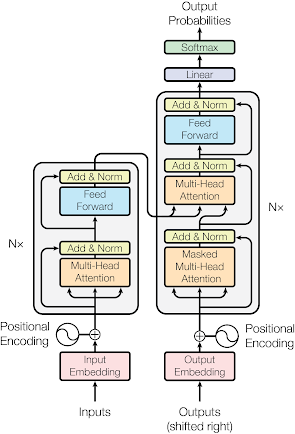
At the heart of many large language models lies the Transformer architecture, which was introduced by Vaswani et al. in the groundbreaking paper "Attention Is All You Need" in 2017. The Transformer architecture has since become the backbone of numerous state-of-the-art language models. It relies on a self-attention mechanism that allows the model to weigh the importance of different words in a sentence, capturing both local and global dependencies within the text. The primary components of the Transformer architecture are:
1. Self-Attention Mechanism:
- The self-attention mechanism lies at the core of Transformers and is responsible for capturing relationships between words in a sentence. It allows the model to assign different weights or attention scores to each word based on its relevance to other words in the sequence. This mechanism enables the model to understand the context and dependencies between words, regardless of their distance from each other.

- In mathematical terms, given an input sequence of embeddings (usually word embeddings), the self-attention mechanism computes attention scores using three learnable matrices: Query, Key, and Value. These matrices are linear transformations of the input embeddings. The attention scores determine how much focus each word should place on other words when computing its representation.
2. Multi-Head Attention:
- Transformers employ multiple self-attention mechanisms, referred to as "heads," to capture different types of relationships between words. Each head is responsible for learning a different aspect of context. For instance, one head might capture syntactic relationships, while another focuses on semantic relationships.
- These different heads work in parallel, and their output representations are concatenated and linearly transformed to produce the final output of the attention layer. Multi-head attention enhances the model's ability to capture diverse patterns and nuances in the input sequence.
3. Positional Encoding:
- Unlike recurrent neural networks (RNNs) or convolutional neural networks (CNNs), Transformers do not inherently understand the order of words in a sequence. To overcome this limitation, positional encodings are added to the input embeddings. These encodings convey information about the position of each word in the sequence, enabling the model to differentiate between words with the same embedding but different positions.
- Positional encodings are usually calculated using trigonometric functions or learned during the training process. They are then added element-wise to the input embeddings before being fed into the model.

4. Feedforward Neural Networks:
- After the self-attention mechanism, the output representations are passed through feedforward neural networks (FFNs). These networks consist of fully connected layers and are applied independently to each position in the sequence.
- The FFNs serve as a transformation layer that further refines the representations captured through self-attention. The non-linear activation functions in FFNs enable the model to learn complex relationships within the input data.
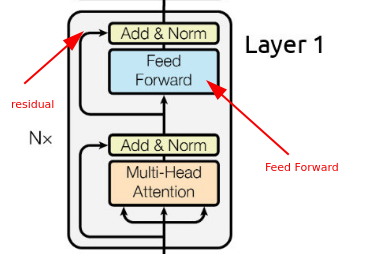
5. Layer Normalization and Residual Connections:
- To ensure stable training and faster convergence, each sub-layer (self-attention and FFN) is followed by layer normalization and a residual connection. The residual connection adds the output of the sub-layer to the original input, effectively allowing the model to learn incremental changes to the input data.
6. Stacking Layers:
- Transformers consist of multiple identical layers stacked on top of each other. This stacking allows the model to learn hierarchical features and abstract representations of the input sequence. Deeper architectures with more layers have been shown to capture richer patterns in the data but also require more computational resources.
- Collectively, these components work in harmony to make Transformers powerful language models capable of understanding, generating, and manipulating human language with impressive accuracy and flexibility.
Historical Evolution of Large Language Models
The journey of large language models began with the introduction of GPT-1 (Generative Pre-trained Transformer 1) by OpenAI in 2018. GPT-1 was a massive leap in natural language processing and demonstrated the capabilities of the Transformer architecture. It was succeeded by GPT-2, which garnered significant attention due to its potential misuse for generating fake news. Despite this, GPT-2 showcased the power of large-scale unsupervised learning.
State-of-the-Art Models and Breakthroughs
The development of large language models took a quantum leap with models like GPT-3, also by OpenAI. GPT-3, released in 2020, pushed the boundaries of scale with a staggering 175 billion parameters. This vast model could perform tasks ranging from language translation to code generation, all based on a few-shot prompt. GPT-3's size and capabilities demonstrated the potential of LLMs in real-world applications.
There were several state-of-the-art models and breakthroughs in the field of AI and machine learning. Here are a few notable models and breakthroughs up until that point:
- GPT-3 and GPT-4: Developed by OpenAI, the Generative Pre-trained Transformer 3 (GPT-3) was one of the most advanced language models at the time. It had 175 billion parameters and demonstrated impressive performance on various language tasks, including translation, text generation, and question-answering.
- BERT: BERT (Bidirectional Encoder Representations from Transformers) revolutionized the field of natural language processing by pretraining a deep bidirectional transformer model on a large text corpus. It achieved state-of-the-art results on a wide range of NLP tasks.
- AlphaFold: DeepMind's AlphaFold made significant progress in the field of protein folding prediction. This breakthrough had the potential to revolutionize drug discovery and bioengineering by accurately predicting the 3D structures of proteins.
- Vision Transformers (ViT): ViT applied the transformer architecture to image recognition tasks and showed that transformers could be successful in the computer vision domain, challenging the dominance of convolutional neural networks (CNNs).
- DALL-E and CLIP: OpenAI introduced DALL-E, a model capable of generating creative and coherent images from textual descriptions, and CLIP, a model that learned to understand images and text together. These models pushed the boundaries of multimodal understanding.
- Reinforcement Learning Advances: There were ongoing breakthroughs in reinforcement learning, with algorithms like DQN, PPO, and SAC achieving impressive results in training agents to play complex games and control systems.
Applications of Large Language Models
The applications of large language models are far-reaching and diverse:
- Natural Language Understanding (NLU): LLMs excel at understanding context and semantics, making them ideal for sentiment analysis, entity recognition, and text classification.
- Natural Language Generation (NLG): These models are used to generate human-like text for chatbots, content creation, and more.
- Machine Translation: LLMs have proven their effectiveness in translating text from one language to another, achieving impressive results in reducing language barriers.
- Text Summarization: These models can automatically summarize long texts, making them valuable tools for information extraction.
- Question Answering: LLMs can be fine-tuned to answer questions based on a given context, enabling intelligent conversational agents.
Implementation: Bringing Transformers to Life
Implementing large language models involves several steps:
- Data Collection: Gather a diverse and extensive dataset that covers the domain of interest.
- Preprocessing: Clean and tokenize the text data, preparing it for input to the model.
- Model Architecture: Build a Transformer-based architecture, adjusting parameters like the number of layers, heads, and dimensions.
- Training: Train the model on the preprocessed data, utilizing powerful hardware and techniques like gradient accumulation.
- Fine-Tuning: Tailor the pre-trained model to specific tasks by fine-tuning on a smaller dataset related to the task.
- Inference: Deploy the trained model for predictions, leveraging the power of GPUs or TPUs for efficient processing.
Fine-tuning an LLM
Fine-tuning a pre-trained large language model (LLM) involves taking a model that has already been trained on a large corpus of text and adapting it to a specific task using a smaller, task-specific dataset. This process allows the LLM to leverage its pre-learned language understanding while tailoring its capabilities to a particular application. Let's go through the steps of fine-tuning a GPT-2 model for sentiment analysis using Python and the Hugging Face Transformers library.
Step 1: Setup and Data Preparation
First, ensure you have the Transformers library installed:
pip install transformersFor demonstration purposes, let's consider a simple sentiment analysis task using a dataset of movie reviews. Download or prepare your sentiment analysis dataset. The dataset should be structured with two columns: "text" for the review text and "label" for sentiment labels (e.g., "positive" or "negative").
Step 2: Load Pretrained Model
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification, AdamW
import torch
# Load pretrained GPT-2 model for sequence classification
model_name = "gpt2" # You can choose other variants like "gpt2-medium", "gpt2-large", etc.
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2ForSequenceClassification.from_pretrained(model_name)
# Modify the model for binary classification
model.config.num_labels = 2Step 3: Prepare Dataset and DataLoader
from torch.utils.data import Dataset, DataLoader
class SentimentDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_length):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
encoding = self.tokenizer(text, truncation=True, padding="max_length", max_length=self.max_length, return_tensors="pt")
input_ids = encoding["input_ids"].squeeze()
attention_mask = encoding["attention_mask"].squeeze()
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": torch.tensor(label)
}
# Assuming you've loaded your dataset into 'train_texts', 'train_labels', 'val_texts', 'val_labels'
train_dataset = SentimentDataset(train_texts, train_labels, tokenizer, max_length=64)
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
val_dataset = SentimentDataset(val_texts, val_labels, tokenizer, max_length=64)
val_dataloader = DataLoader(val_dataset, batch_size=8)Step 4: Fine-Tuning Loop
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = AdamW(model.parameters(), lr=2e-5)
for epoch in range(5): # You can adjust the number of epochs
model.train()
total_loss = 0
for batch in train_dataloader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_dataloader)
print(f"Epoch {epoch+1}/{5} - Average Loss: {avg_loss:.4f}")
# After training, evaluate the model on the validation set
model.eval()
correct = 0
with torch.no_grad():
for batch in val_dataloader:
input_ids = batch["input_ids"].to(device)
attention_mask = batch["attention_mask"].to(device)
labels = batch["labels"].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
predictions = torch.argmax(outputs.logits, dim=1)
correct += torch.sum(predictions == labels).item()
accuracy = correct / len(val_dataset)
print(f"Validation Accuracy: {accuracy:.2%}")In this example, we used a pretrained GPT-2 model and fine-tuned it for binary sentiment classification on a custom dataset. The process involves loading the model, preparing the dataset, setting up a fine-tuning loop, and evaluating the model's performance. You can customize this approach for other tasks by adapting the dataset and adjusting the training parameters.
Conclusion
Large language models, driven by the transformative architecture of Transformers, have ushered in a new era of natural language processing. These models have demonstrated unprecedented capabilities in understanding and generating human language, opening up a world of possibilities in various domains. As research and development in this field continue, we can anticipate even more advanced language models that will shape the future of human-computer interaction and communication.
Comments
Post a Comment