
Machine learning algorithms have revolutionized the way we extract insights and make sense of vast amounts of data. One of the fundamental tasks in machine learning is measuring the similarity between objects, whether they are text documents, images, or any other form of data. Cosine similarity is a powerful technique that has emerged as a popular choice for quantifying similarity in machine learning applications. In this blog post, we will explore the concept of cosine similarity, its mathematical foundation, its applications in various domains, and how it can be implemented using TensorFlow framework.
What is Cosine Similarity?
Cosine similarity is a metric used to determine how similar two vectors are, regardless of their magnitude. It measures the cosine of the angle between two vectors projected into a multidimensional space. The resulting value ranges from -1 to 1, where 1 represents perfect similarity, 0 indicates no similarity, and -1 indicates perfect dissimilarity. The key advantage of cosine similarity is that it is insensitive to the vector magnitude, making it useful for comparing documents or objects of different lengths.
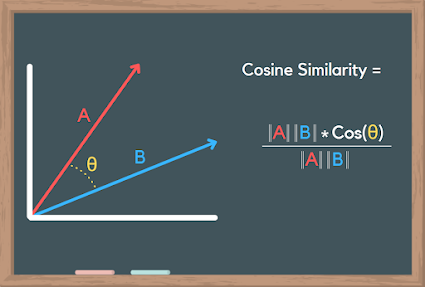
Mathematical Foundation:
To understand how cosine similarity works, let's consider two vectors, A and B, in an n-dimensional space. The cosine similarity between these vectors is calculated using the dot product of the vectors divided by the product of their magnitudes. Mathematically, it can be expressed as:
$cosine_similarity(A, B) = (A . B) / (||A|| * ||B||)$
Here, (A . B) represents the dot product of vectors A and B, while ||A|| and ||B|| denote the magnitudes of vectors A and B, respectively. By computing this equation, we obtain a similarity score between -1 and 1.
Applications of Cosine Similarity in Machine Learning:
- Cosine similarity finds applications in various machine learning tasks, including:
- Document Similarity: In natural language processing, cosine similarity is widely used to measure the similarity between text documents. By representing documents as vectors, where each dimension corresponds to a specific term or word, we can determine how closely related two documents are.
- Information Retrieval: Cosine similarity helps in building effective search engines by comparing user queries with a large corpus of documents. By calculating the cosine similarity between the query vector and document vectors, search engines can retrieve the most relevant documents.
- Clustering: Cosine similarity plays a crucial role in clustering algorithms such as k-means. It helps identify groups of similar objects by measuring the cosine similarity between their feature vectors.
- Recommendation Systems: Cosine similarity is employed in recommendation systems to find similar items or users. By comparing user preferences or item attributes, recommendations can be made based on cosine similarity scores.
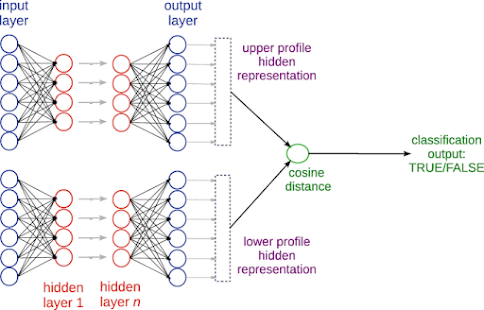
Implementing Cosine Similarity in TensorFlow:
Now, let's dive into implementing cosine similarity using TensorFlow, a powerful machine learning library.
import tensorflow as tf
def cosine_similarity(A, B):
dot_product = tf.reduce_sum(tf.multiply(A, B), axis=1)
norm_A = tf.norm(A, axis=1)
norm_B = tf.norm(B, axis=1)
similarity = dot_product / (norm_A * norm_B)
return similarityIn the code snippet above, we define a function 'cosine_similarity' that takes two tensors, A and B, as inputs. Using TensorFlow's mathematical operations, we calculate the dot product of A and B using 'tf.reduce_sum' and element-wise multiplication 'tf.multiply'. We also compute the magnitudes of A and B using 'tf.norm'. Finally, we divide the dot product by the product of the magnitudes to obtain the cosine similarity.
Neural Network with Cosine Similarity Loss
Here is an example implementation of a neural network using cosine similarity as a similarity metric. We'll build a simple feedforward neural network using TensorFlow and utilize cosine similarity as the loss function.
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras.losses import cosine_similarity
# Define the neural network model
def create_model(input_shape):
model = tf.keras.Sequential()
model.add(Dense(128, activation='relu', input_shape=input_shape))
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
return model
# Create the model
input_shape = (10,) # Example input shape
model = create_model(input_shape)
# Compile the model with cosine similarity loss
model.compile(optimizer='adam', loss=cosine_similarity, metrics=['accuracy'])
# Train the model
x_train = ... # Training data
y_train = ... # Training labels
model.fit(x_train, y_train, epochs=10, batch_size=32)
# Evaluate the model
x_test = ... # Test data
y_test = ... # Test labels
loss, accuracy = model.evaluate(x_test, y_test)
print(f"Loss: {loss}, Accuracy: {accuracy}")In the code snippet above, we first define a function create_model that creates a feedforward neural network model using the Keras API in TensorFlow. It consists of multiple dense layers with ReLU activation functions, and the final layer uses a sigmoid activation for binary classification.
Next, we compile the model using the cosine_similarity loss function. By specifying loss=cosine_similarity, we instruct the model to optimize the network parameters based on cosine similarity as the loss metric. We also include accuracy as a metric to monitor the performance during training.
After compiling the model, we can train it by providing the training data x_train and labels y_train to the fit method. In this example, we use 10 epochs and a batch size of 32, but you can adjust these values according to your specific requirements.
Finally, we evaluate the trained model on test data x_test and labels y_test using the evaluate method. This provides us with the loss value and accuracy of the model on the test set.
By using cosine similarity as the loss function, the neural network is trained to optimize the parameters in a way that maximizes similarity between predicted and target values. This approach can be beneficial in tasks where similarity is a crucial factor, such as recommendation systems or content matching.
Wrap-up
Cosine similarity is a powerful tool in machine learning that allows us to measure the similarity between vectors, regardless of their magnitudes. Its mathematical foundation, which involves calculating the cosine of the angle between two vectors, makes it suitable for a wide range of applications in various domains.
In this blog post, we explored the concept of cosine similarity, its mathematical formulation, and its significance in machine learning. We discussed its applications in tasks such as document similarity, information retrieval, clustering, and recommendation systems. Cosine similarity has proven to be a valuable metric for quantifying similarity and has contributed to the development of robust machine learning algorithms.
Furthermore, we provided a TensorFlow implementation of cosine similarity, demonstrating how it can be easily incorporated into machine learning models. TensorFlow, with its extensive set of mathematical operations and efficient computation capabilities, enables us to leverage cosine similarity in a flexible and scalable manner.
As machine learning continues to advance and become more pervasive in various industries, understanding and utilizing techniques like cosine similarity becomes increasingly important. By grasping the concepts and implementations, we can unlock the potential of cosine similarity to improve search engines, recommendation systems, clustering algorithms, and more.
In conclusion, cosine similarity is a valuable tool that empowers machine learning algorithms to quantify similarity and enable intelligent decision-making. Its simplicity, effectiveness, and versatility make it a fundamental concept for anyone venturing into the world of machine learning and data analysis. So, embrace the power of cosine similarity and explore the numerous possibilities it offers in your machine learning endeavors.
Comments
Post a Comment