
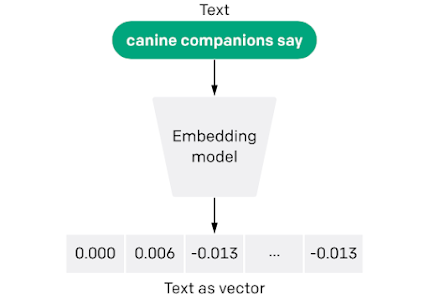
In machine learning, vector embeddings are a mathematical technique used to represent high-dimensional data in a lower-dimensional space. They are commonly used in Natural Language Processing (NLP) to transform words or phrases into dense numerical vectors that can be used as inputs for machine learning models. Each dimension of the vector corresponds to a feature or attribute of the input data, and the values within each dimension indicate the degree to which that feature is present in the data.
Vector embeddings are often used in NLP tasks such as sentiment analysis, language translation, and text classification, and have also found applications in other areas such as image and audio processing.
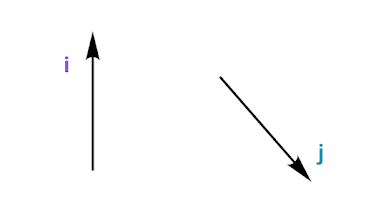
Mathematical Vector
In mathematics, a vector is a mathematical object that has both magnitude (or length) and direction. Vectors can be represented as arrows in a 2D or 3D space, where the length of the arrow represents the magnitude of the vector and the direction of the arrow represents its direction. Vectors can be added, subtracted, and scaled to perform mathematical operations.
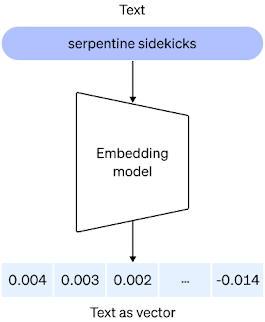
Machine learning vector
In machine learning, vectors are used to represent data points in a high-dimensional space. These vectors are often referred to as "feature vectors" because they represent the features of the data point. For example, in NLP, a sentence can be represented as a vector of word embeddings, where each word is assigned a vector representation based on its meaning in the context of the sentence. These vector representations capture the semantic meaning of the sentence in a high-dimensional space and can be used for various NLP tasks such as sentiment analysis, text classification, and machine translation.
In contrast to physics vectors which are utilized to depict and examine physical quantities in the real world, mathematical vectors are arbitrary and do not necessarily adhere to physical properties or rules. As an illustration, vector embeddings produced by OpenAI have 1536 dimensions.
How is this possible? We only have 3 dimensions, right? RIGHT!
To clarify, while physical vectors are typically limited to 3 dimensions to represent physical quantities in the real world, mathematical vectors can have any number of dimensions and are not constrained by physical properties. In the context of natural language processing, high-dimensional vectors are needed to accurately capture the complex relationships and meanings between words and phrases. OpenAI's generated vector embeddings, for example, have 1536 dimensions to capture a wide range of semantic features.
What are vector embeddings?
That was a great explanation so far! To add to it, vector embeddings are also useful in capturing semantic and syntactic relationships between words, which can help NLP models understand the context of words and sentences. For example, similar words such as "cat" and "dog" are likely to have similar vector embeddings, while dissimilar words such as "cat" and "table" are likely to have dissimilar vector embeddings. This allows NLP models to perform tasks such as word similarity, analogical reasoning, and even generate coherent and meaningful text.
To represent a sentence as a vector, there are several techniques available. One of the commonly used methods involves using word embedding algorithms such as Word2Vec, GloVe, or FastText to create word-level embeddings, and then aggregating them to form a sentence-level vector representation. However, this method may not capture the nuances of word order or complex structures. A more advanced approach is to use pre-trained language models such as BERT or GPT, which can provide contextualized embeddings for entire sentences.
These models are based on deep learning architectures such as Transformers, which can capture the contextual information and relationships between words in a sentence more effectively. This allows for better representation of the meaning of the sentence, including the nuances of language and context.
Implementation of Word2vec, GloVE, and FasText in TensrFlow:
1. Word2Vec:
Word2Vec is an unsupervised learning algorithm that aims to generate word embeddings using a neural network. It is based on a two-layer neural network that is trained to predict the probability of a word given its context or vice versa.
To implement Word2Vec in TensorFlow, you can use the TensorFlow library's implementation of Word2Vec. Here's a sample code:
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import skipgrams
# Create the tokenizer
tokenizer = Tokenizer()
# Fit the tokenizer on the text data
tokenizer.fit_on_texts(text_data)
# Create the sequence of token IDs
sequences = tokenizer.texts_to_sequences(text_data)
# Generate skip-gram pairs
skip_grams = skipgrams(
sequence,
vocabulary_size=len(tokenizer.word_index),
window_size=4)
# Define the Word2Vec model
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(
input_dim=len(tokenizer.word_index),
output_dim=300),
tf.keras.layers.Lambda(lambda x: tf.reduce_mean(x, axis=1)),
tf.keras.layers.Dense(
units=len(tokenizer.word_index),
activation='softmax')
])
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
# Train the model
model.fit(x=[pair[0] for pair in skip_grams],
y=[pair[1] for pair in skip_grams],
epochs=50,
batch_size=256)
2. GloVe:
GloVe (Global Vectors) is also an unsupervised learning algorithm that generates word embeddings. It is based on the co-occurrence matrix of words, and the objective is to learn vector representations that capture the semantic meaning of words.
To implement GloVe in TensorFlow, you can use the GloVe library, which provides pre-trained word vectors. Here's an example code:
import tensorflow as tf
from glove import Glove
# Load the pre-trained word vectors
glove = Glove.load('path/to/glove_model')
# Get the word vector for a particular word
word_vector = glove.word_vectors[glove.dictionary['word']]
# Get the most similar words for a particular word
similar_words = glove.most_similar('word', number=10)
3. FastText:
FastText is a supervised learning algorithm that generates word embeddings using character n-grams. It is based on a neural network that predicts the probability of a word given its character n-grams.
To implement FastText in TensorFlow, you can use the TensorFlow library's implementation of FastText. Here's a sample code:
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import skipgrams
# Create the tokenizer
tokenizer = Tokenizer()
# Fit the tokenizer on the text data
tokenizer.fit_on_texts(text_data)
# Create the sequence of token IDs
sequences = tokenizer.texts_to_sequences(text_data)
# Define the FastText model
model = tf.keras.models.Sequential([
tf.keras.layers.Embedding(
input_dim=len(tokenizer.word_index),
output_dim=300),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(
units=len(tokenizer.word_index),
activation='softmax')
])
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
# Train the model
model.fit(x=sequences,
y=labels,
epochs=50,
Comments
Post a Comment