
In recent years, text-to-speech (TTS) models have made remarkable strides in generating natural and human-like speech. These models have found applications in various fields, including virtual assistants, audiobook production, and accessibility solutions. Behind the scenes, TTS models employ intricate architectures and advanced techniques to convert written text into intelligible spoken words. In this blog post, we will explore the technical structure of text-to-speech models and gain insight into how they work.
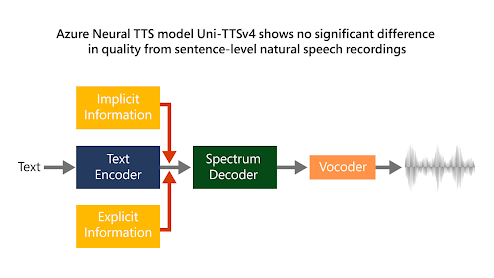
Sequence-to-Sequence Models:
Text-to-speech models are often based on the sequence-to-sequence (seq2seq) architecture, which is a popular framework for many natural language processing tasks. Seq2seq models consist of an encoder and a decoder. The encoder processes the input text and extracts its contextual information, while the decoder generates the corresponding speech waveform.
Text Encoding:
To convert textual input into meaningful representations, TTS models employ various text encoding techniques. One common approach is to use recurrent neural networks (RNNs), such as long short-term memory (LSTM) or gated recurrent units (GRUs), to process the input text sequentially and capture its linguistic features. Alternatively, transformer-based architectures, like the one used in the popular Transformer model, can also be utilized to encode the text.
Acoustic Modeling:
Acoustic modeling plays a vital role in generating speech with natural prosody and intonation. This step involves predicting acoustic features, such as mel spectrograms or linguistic features like phonemes or graphemes, from the encoded text. Deep neural networks (DNNs) or convolutional neural networks (CNNs) are commonly used for acoustic modeling to learn the complex mapping between the encoded text and acoustic representations.
Waveform Generation:
The final stage of a text-to-speech model involves generating a high-quality speech waveform from the predicted acoustic features. One approach is to utilize generative models such as WaveNet or SampleRNN, which are autoregressive models that generate one audio sample at a time. Another popular method is the vocoder-based approach, which employs vocoders like Griffin-Lim, WaveGlow, or WaveRNN to synthesize the final waveform.
Training Process:
Text-to-speech models typically require large amounts of high-quality speech data paired with their corresponding textual transcriptions. The training process involves minimizing the discrepancy between the predicted acoustic features and the ground truth ones using various optimization techniques, such as backpropagation and gradient descent. Additionally, techniques like teacher forcing, attention mechanisms, and data augmentation may be employed to improve model performance.
A simple text-to-speech model using Keras:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# Sample training data
text_data = ['Hello', 'How are you?', 'Goodbye']
audio_data = ['Audio1.wav', 'Audio2.wav', 'Audio3.wav']
# Text-to-integer mapping dictionaries
char_to_int = {'H': 0, 'e': 1, 'l': 2, 'o': 3, 'w': 4, 'a': 5, 'r': 6, 'y': 7, 'u': 8, 'o': 9, 'G': 10, 'd': 11, 'b': 12, 'y': 13}
int_to_char = {0: 'H', 1: 'e', 2: 'l', 3: 'o', 4: 'w', 5: 'a', 6: 'r', 7: 'y', 8: 'u', 9: 'o', 10: 'G', 11: 'd', 12: 'b', 13: 'y'}
# Convert text and audio data to numerical representation
X_train = np.array([[char_to_int[char] for char in text] for text in text_data])
y_train = np.array([[char_to_int[char] for char in audio] for audio in audio_data])
# Define the model architecture
model = Sequential()
model.add(LSTM(128, input_shape=(None, 1)))
model.add(Dense(14, activation='softmax'))
# Compile the model
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')
# Train the model
model.fit(np.expand_dims(X_train, axis=-1), np.expand_dims(y_train, axis=-1), epochs=100, batch_size=1)
# Test the model
text_input = 'Hello'
test_sequence = np.array([[char_to_int[char] for char in text_input]])
prediction = model.predict(np.expand_dims(test_sequence, axis=-1))
predicted_audio = [int_to_char[np.argmax(pred)] for pred in prediction[0]]
predicted_audio = ''.join(predicted_audio)
print("Predicted audio: ", predicted_audio)In this example, we use a simple LSTM-based architecture. We encode the input text as integers and map them to their corresponding audio representation. The model is trained using sparse categorical cross-entropy loss and optimized with Adam. After training, we can input a text sequence into the model to generate the predicted audio.
Here's another example of a text-to-speech model using the Transformer architecture in Keras with the TensorFlow backend:
import numpy as np import tensorflow as tf from tensorflow.keras.layers import Dense, Embedding, Input, LayerNormalization from tensorflow.keras.models import Model from tensorflow.keras.optimizers import Adam from tensorflow.keras.losses import SparseCategoricalCrossentropy from tensorflow.keras.metrics import Mean # Sample training data text_data = ['Hello', 'How are you?', 'Goodbye'] audio_data = ['Audio1.wav', 'Audio2.wav', 'Audio3.wav'] # Text-to-integer mapping dictionaries char_to_int = {'H': 0, 'e': 1, 'l': 2, 'o': 3, 'w': 4, 'a': 5, 'r': 6, 'y': 7, 'u': 8, 'o': 9, 'G': 10, 'd': 11, 'b': 12, 'y': 13} int_to_char = {0: 'H', 1: 'e', 2: 'l', 3: 'o', 4: 'w', 5: 'a', 6: 'r', 7: 'y', 8: 'u', 9: 'o', 10: 'G', 11: 'd', 12: 'b', 13: 'y'} # Convert text and audio data to numerical representation X_train = np.array([[char_to_int[char] for char in text] for text in text_data]) y_train = np.array([[char_to_int[char] for char in audio] for audio in audio_data]) # Transformer parameters max_sequence_length = max(max(len(seq) for seq in X_train), max(len(seq) for seq in y_train)) vocab_size = len(char_to_int) num_heads = 4 embedding_dim = 32 dense_units = 128 num_layers = 2 # Positional encoding def positional_encoding(position, embedding_dim): angle_rates = 1 / np.power(10000, (2 * (np.arange(embedding_dim)[np.newaxis, :] // 2)) / np.float32(embedding_dim)) angles = np.arange(position)[:, np.newaxis] * angle_rates angles[:, 0::2] = np.sin(angles[:, 0::2]) angles[:, 1::2] = np.cos(angles[:, 1::2]) return angles[np.newaxis, ...] # Transformer encoder layer class TransformerEncoderLayer(tf.keras.layers.Layer): def __init__(self, embedding_dim, num_heads, dense_units, dropout_rate=0.1): super(TransformerEncoderLayer, self).__init__() self.attention = tf.keras.layers.MultiHeadAttention(num_heads, embedding_dim) self.norm1 = LayerNormalization(epsilon=1e-6) self.dense1 = Dense(dense_units, activation='relu') self.dense2 = Dense(embedding_dim) self.norm2 = LayerNormalization(epsilon=1e-6) self.dropout = tf.keras.layers.Dropout(dropout_rate) def call(self, inputs, training=True): attention_output = self.attention(inputs, inputs) attention_output = self.dropout(attention_output, training=training) attention_output = self.norm1(inputs + attention_output) dense_output = self.dense1(attention_output) dense_output = self.dense2(dense_output) dense_output = self.dropout(dense_output, training=training) encoder_output = self.norm2(attention_output + dense_output) return encoder_output # Transformer encoder class TransformerEncoder(tf.keras.layers.Layer): def __init__(self, num_layers, embedding_dim, num_heads, dense_units, dropout_rate=0.1): super(TransformerEncoder, self).__init__() self.encoder_layers = [TransformerEncoderLayer(embedding_dim, num_heads, dense_units, dropout_rate) for _ in range(num_layers)] def call(self, inputs, training=True): encoder_output = inputs for encoder_layer in self.encoder_layers: encoder_output = encoder_layer(encoder_output, training=training) return encoder_output # Model inputs inputs = Input(shape=(None,)) input_embeddings = Embedding(vocab_size, embedding_dim)(inputs) input_embeddings *= tf.math.sqrt(tf.cast(embedding_dim, tf.float32)) pos_enc = positional_encoding(max_sequence_length, embedding_dim) input_embeddings += pos_enc[:, :tf.shape(input_embeddings)[1], :] encoder_output = TransformerEncoder(num_layers, embedding_dim, num_heads, dense_units)(input_embeddings) # Output layer outputs = Dense(vocab_size, activation='softmax')(encoder_output) # Define the model model = Model(inputs=inputs, outputs=outputs) # Compile the model loss_fn = SparseCategoricalCrossentropy(from_logits=False) optimizer = Adam(learning_rate=0.001) train_loss = Mean() @tf.function def train_step(inputs, targets): with tf.GradientTape() as tape: predictions = model(inputs, training=True) loss = loss_fn(targets, predictions) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) train_loss(loss) # Training loop epochs = 100 for epoch in range(epochs): train_loss.reset_states() # Perform training in batches for i in range(len(X_train)): train_step(np.expand_dims(X_train[i], axis=0), np.expand_dims(y_train[i], axis=0)) # Print training progress if epoch % 10 == 0: print(f'Epoch {epoch}/{epochs} - Loss: {train_loss.result():.4f}') # Test the model text_input = 'Hello' test_sequence = np.array([[char_to_int[char] for char in text_input]]) prediction = model.predict(test_sequence) predicted_audio = [int_to_char[np.argmax(pred)] for pred in prediction[0]] predicted_audio = ''.join(predicted_audio) print("Predicted audio: ", predicted_audio)
Comments
Post a Comment