
Fine-tuning GPT-3 on a specific dataset can improve its performance on a particular task. In this blog, we will go over the process of fine-tuning GPT-3 and explain the technical aspects involved in the process. We will use the Hugging Face library to fine-tune the model and Python programming language.
What is GPT-3?
Generative Pre-trained Transformer 3 (GPT-3) is a state-of-the-art language model developed by OpenAI. It has been trained on a massive amount of text data and can generate human-like text with high accuracy. GPT-3 is a transformer-based model that uses unsupervised learning to learn the patterns and relationships in the language data.
What is fine-tuning?
Fine-tuning is a technique used to adapt a pre-trained model to a specific task or dataset. In the case of GPT-3, we can fine-tune the model on a specific dataset to improve its performance on a particular task. Fine-tuning involves training the model on a smaller dataset, using supervised learning, to update the model's parameters to fit the task or data.
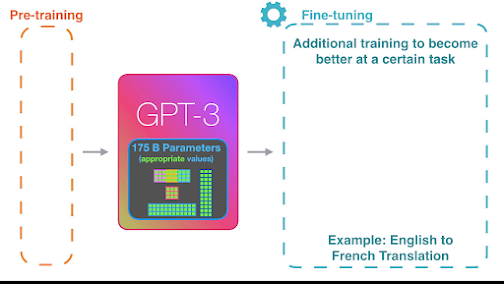
Source: https://jalammar.github.io/how-gpt3-works-visualizations-animations/
Fine-tuning GPT-3
To fine-tune GPT-3, we will use the Hugging Face library, which provides an easy-to-use API for fine-tuning and using pre-trained models. The library has pre-built modules for fine-tuning language models, including GPT-3.
Step 1: Install the Hugging Face library
To get started, we need to install the Hugging Face library. We can use pip to install the library:
!pip install transformers
Step 2: Load the pre-trained GPT-3 model
Next, we need to load the pre-trained GPT-3 model. We can use the 'GPT3LMHeadModel' class from the Hugging Face library to load the pre-trained model.
from transformers import GPT3LMHeadModel, GPT3Tokenizer
model = GPT3LMHeadModel.from_pretrained('gpt3')
tokenizer = GPT3Tokenizer.from_pretrained('gpt3')Step 3: Prepare the dataset
Before we can fine-tune the GPT-3 model, we need to prepare the dataset. The dataset should be in a text format, and each example should be separated by a newline character.
with open('dataset.txt', 'r') as f:
dataset = f.read()Step 4: Tokenize the dataset
Next, we need to tokenize the dataset using the GPT-3 tokenizer. The tokenizer will split the text into tokens that the model can process.
inputs = tokenizer(dataset, return_tensors='pt')Step 5: Fine-tune the model
Now that we have prepared the dataset and tokenized it, we can fine-tune the GPT-3 model. We will use the Trainer class from the Hugging Face library to fine-tune the model.
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=1,
per_device_train_batch_size=4,
save_steps=10_000,
save_total_limit=2
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=inputs
)
trainer.train()Step 6: Save the fine-tuned model
Finally, we can save the fine-tuned model for future use.
trainer.save_model('fine-tuned-gpt3')
Summary
Fine-tuning GPT-3 on a specific dataset can improve its performance on a particular task. In this blog, we have explained the technical aspects of fine-tuning GPT-3 using the Hugging Face library and Python programming language.
We started by loading the pre-trained GPT-3 model and preparing the dataset by tokenizing it. Then, we fine-tuned the model using the Trainer class from the Hugging Face library and saved the fine-tuned model for future use.
Fine-tuning GPT-3 can be a time-consuming process, and it requires a powerful computer with a lot of memory. However, the benefits of fine-tuning the model on a specific dataset can be significant, and it can improve the model's performance on a particular task.
In addition to the steps mentioned above, there are many hyperparameters that can be tuned to fine-tune the GPT-3 model, such as learning rate, batch size, and number of epochs. These hyperparameters can have a significant impact on the performance of the fine-tuned model, and they should be carefully selected based on the specific task and dataset.
Comments
Post a Comment