
With a pre-trained "teacher" network, teacher-student training is a method for accelerating training and enhancing the convergence of a neural network. It is widely used to train smaller, less expensive networks from more expensive, larger ones since it is both popular and effective. In a previous post, we discussed the concept of Knowlege Distillation as the idea behind the Teacher-Student model. In this post, we'll discuss the fundamentals of teacher-student training, demonstrate how to do it in PyTorch, and examine the results of using this approach. If you're not familiar with softmax cross entropy, our introduction to it might be a helpful pre-read. This is a part of our series on training targets.
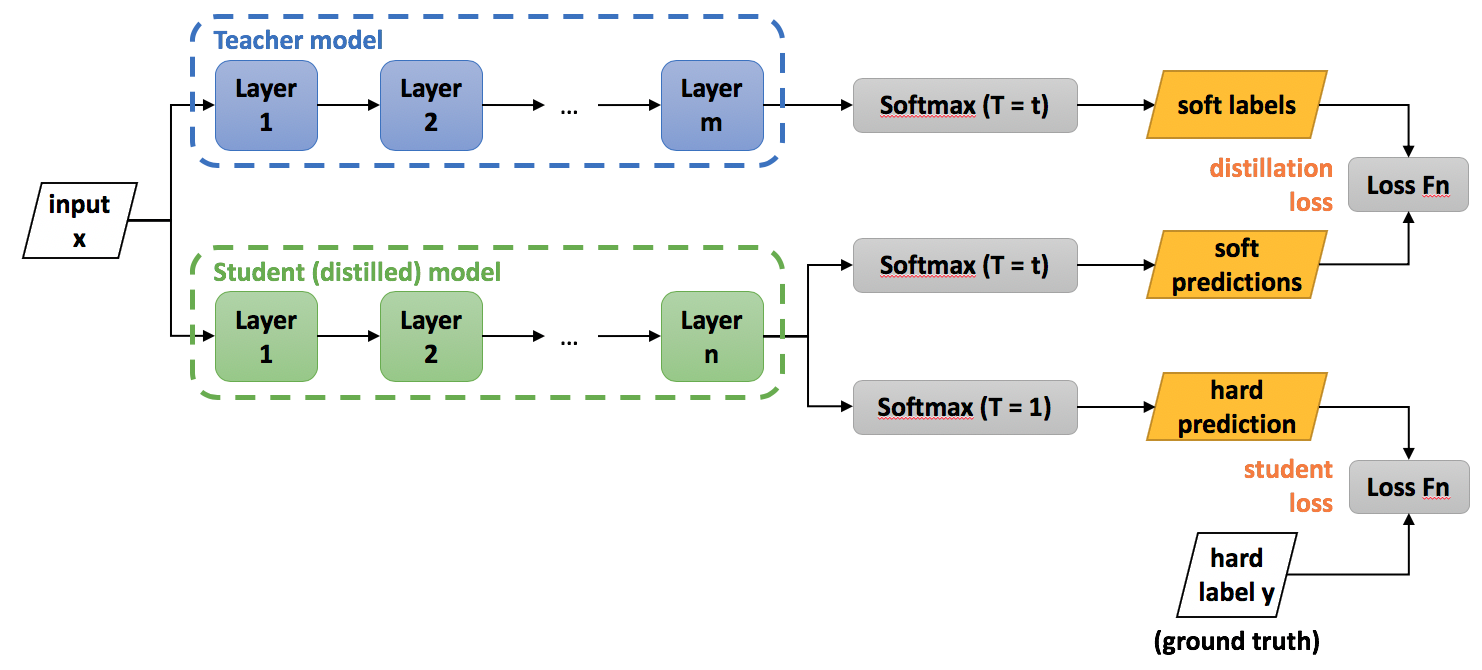
Main Concept
The concept is basic. Start by training a sizable neural network (the teacher) with training data as per normal. Then, build a second, smaller network (the student), and train it to replicate the teacher's outcomes. For instance, teacher preparation might look like this:
for (batch_idx, batch) in enumerate(train_ldr):
X = batch[0] # the predictors / inputs
Y = batch[1] # the targets
out = teacher(X)
. . .But training the student looks like:
for (batch_idx, batch) in enumerate(train_ldr):
X = batch[0] # the predictors / inputs
Y = teacher(X) # outputs from the teacher
out = student(X)
. . . The teacher-student technique can be applied in a variety of ways because it is only a basic idea rather than a predetermined procedure. I've already looked at teacher-student relationships, but I wanted to review the concepts. I applied one of my typical instances of multi-class classification, where the objective is to predict a person's political leaning (conservative, moderate, or liberal) based on their gender, age, state (Michigan, Nebraska, or Oklahoma), and income. The data after normalization and encoding looks like:
# sex age state income politics
1 0.24 1 0 0 0.2950 2
-1 0.39 0 0 1 0.5120 1
1 0.63 0 1 0 0.7580 0
-1 0.36 1 0 0 0.4450 1
. . .We created a large teacher network with 6-(10-10)-3 architecture and trained it using NLLLoss(). Then we created a small student network with a 6-8-3 architecture and trained it using MSELoss(). Both networks had similar classification accuracy, which indicates the teacher-student technique succeeded in finding a condensed version of the original large network.
The train and test data are here:
import numpy as np
import torch as T
device = T.device('cpu') # apply to Tensor or Module
# -----------------------------------------------------------
class PeopleDataset(T.utils.data.Dataset):
# sex age state income politics
# -1 0.27 0 1 0 0.7610 2
# +1 0.19 0 0 1 0.6550 0
# sex: -1 = male, +1 = female
# state: michigan, nebraska, oklahoma
# politics: conservative, moderate, liberal
def __init__(self, src_file):
tmp_x = np.loadtxt(src_file, usecols=range(0,6),
delimiter="\t", dtype=np.float32)
tmp_y = np.loadtxt(src_file, usecols=6,
delimiter="\t", dtype=np.int64) # 1d required
self.x_data = T.tensor(tmp_x, dtype=T.float32).to(device)
self.y_data = T.tensor(tmp_y, dtype=T.int64).to(device)
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
preds = self.x_data[idx]
trgts = self.y_data[idx]
return (preds, trgts) # as Tuple
# -----------------------------------------------------------
class TeacherNet(T.nn.Module):
def __init__(self):
super(TeacherNet, self).__init__()
self.hid1 = T.nn.Linear(6, 10) # 6-(10-10)-3
self.hid2 = T.nn.Linear(10, 10)
self.oupt = T.nn.Linear(10, 3)
T.nn.init.xavier_uniform_(self.hid1.weight)
T.nn.init.zeros_(self.hid1.bias)
T.nn.init.xavier_uniform_(self.hid2.weight)
T.nn.init.zeros_(self.hid2.bias)
T.nn.init.xavier_uniform_(self.oupt.weight)
T.nn.init.zeros_(self.oupt.bias)
def forward(self, x):
z = T.tanh(self.hid1(x))
z = T.tanh(self.hid2(z))
z = T.log_softmax(self.oupt(z), dim=1) # NLLLoss()
return z
# -----------------------------------------------------------
class StudentNet(T.nn.Module):
def __init__(self):
super(StudentNet, self).__init__()
self.hid1 = T.nn.Linear(6, 8) # 6-8-3
self.oupt = T.nn.Linear(8, 3)
T.nn.init.xavier_uniform_(self.hid1.weight)
T.nn.init.zeros_(self.hid1.bias)
T.nn.init.xavier_uniform_(self.oupt.weight)
T.nn.init.zeros_(self.oupt.bias)
def forward(self, x):
z = T.tanh(self.hid1(x))
z = self.oupt(z) # no activation for MSELoss()
return z
# -----------------------------------------------------------
def accuracy(model, ds):
# assumes model.eval()
n_correct = 0; n_wrong = 0
for i in range(len(ds)):
X = ds[i][0].reshape(1,-1) # make it a batch
Y = ds[i][1].reshape(1) # 0 1 or 2
with T.no_grad():
oupt = model(X) # logits form
big_idx = T.argmax(oupt) # 0 or 1 or 2
if big_idx == Y:
n_correct += 1
else:
n_wrong += 1
acc = (n_correct * 1.0) / (n_correct + n_wrong)
return acc
# -----------------------------------------------------------
def main():
# 0. get started
print("\nBegin Teacher-Student NN demo ")
T.manual_seed(0)
np.random.seed(0)
# 1. create datasets objects
print("\nCreating teacher network Datasets ")
train_file = ".\\Data\\people_train.txt"
train_ds = PeopleDataset(train_file) # 200 rows
test_file = ".\\Data\\people_test.txt"
test_ds = PeopleDataset(test_file) # 40 rows
bat_size = 10
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True)
# 2. create network
print("\nCreating 6-(10-10)-3 teacher network ")
teacher = TeacherNet().to(device)
teacher.train() # set mode
# 3. train the teacher NN
max_epochs = 2000
ep_log_interval = 500
lrn_rate = 0.005
# max_epochs = 20
# ep_log_interval = 2
# lrn_rate = 0.005
loss_func = T.nn.NLLLoss() # assumes log-softmax()
optimizer = T.optim.SGD(teacher.parameters(), lr=lrn_rate)
print("\nbat_size = %3d " % bat_size)
print("loss = " + str(loss_func))
print("optimizer = SGD")
print("max_epochs = %3d " % max_epochs)
print("lrn_rate = %0.3f " % lrn_rate)
print("\nStarting training the teacher NN")
for epoch in range(0, max_epochs):
epoch_loss = 0 # for one full epoch
for (batch_idx, batch) in enumerate(train_ldr):
X = batch[0]
Y = batch[1]
optimizer.zero_grad()
oupt = teacher(X)
loss_val = loss_func(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
loss_val.backward()
optimizer.step()
if epoch % ep_log_interval == 0:
print("epoch = %4d loss = %0.4f" % (epoch, epoch_loss))
print("Done ")
# 4. evaluate model accuracy
print("\nComputing teacher model accuracy")
teacher.eval()
acc_train = accuracy(teacher, train_ds) # item-by-item
print("Teacher accuracy on training data = %0.4f" % acc_train)
acc_test = accuracy(teacher, test_ds) # item-by-item
print("Teacher accuracy on test data = %0.4f" % acc_test)
# 5. create and train Student NN
print("\nCreating 6-8-3 student NN")
student = StudentNet()
student.train() # set mode
# 6. recreate Dataset and DataLoader
train_file = ".\\Data\\people_train.txt"
train_ds = PeopleDataset(train_file) # 200 rows
test_file = ".\\Data\\people_test.txt"
test_ds = PeopleDataset(test_file) # 40 rows
bat_size = 10
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True)
# 7. train student NN
max_epochs = 2000
ep_log_interval = 500
lrn_rate = 0.005
loss_func = T.nn.MSELoss() # no hidden activation
optimizer = T.optim.SGD(student.parameters(), lr=lrn_rate)
print("\nbat_size = %3d " % bat_size)
print("loss = " + str(loss_func))
print("optimizer = SGD")
print("max_epochs = %3d " % max_epochs)
print("lrn_rate = %0.3f " % lrn_rate)
print("\nStarting training the student NN ")
for epoch in range(0, max_epochs):
epoch_loss = 0 # for one full epoch
for (batch_idx, batch) in enumerate(train_ldr):
X = batch[0]
# Y = batch[1]
Y = teacher(X) # log_softmax logits output from teacher
optimizer.zero_grad()
oupt = student(X) # outputs from Student
loss_val = loss_func(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
loss_val.backward()
optimizer.step()
if epoch % ep_log_interval == 0:
print("epoch = %4d loss = %0.4f" % (epoch, epoch_loss))
print("Done ")
# 8. evaluate student model accuracy
print("\nComputing student model accuracy")
student.eval()
acc_train = accuracy(student, train_ds) # item-by-item
print("Student accuracy on training data = %0.4f" % acc_train)
acc_test = accuracy(student, test_ds) # item-by-item
print("Student accuracy on test data = %0.4f" % acc_test)
# 9. TODO: save trained student model
print("\nEnd Teacher-Student NN demo")
if __name__ == "__main__":
main()
Summary
This was the teacher-student model, which is most frequently used to distill knowledge. This target can be justified as being less "spiky" than one-hot softmax cross entropy. We learned what kinds of gradients to anticipate, that even the correct class can experience a positive loss gradient, and that when the student agrees with the mixed objective, the gradient is zero.
The most typical teacher-student scenario is optimizing for inference/predictions, where we aim for the highest prediction quality at the shortest possible prediction duration. In order to accomplish this, we are prepared to invest more training time in a huge teacher before using the teacher-student aim to train a compact student model more effectively than we could have otherwise.
Comments
Post a Comment