
Self-training with Noisy Student is a popular semi-supervised learning technique in deep learning that has been shown to significantly improve model performance by using unlabeled data. It is especially useful when labeled data is scarce or expensive to obtain. In this short blog post, we will discuss what self-training with Noisy Student is, how it works, and how to implement it in PyTorch.
What is Self-Training with Noisy Student?
Self-training with Noisy Student is a semi-supervised learning technique that uses a self-supervised pre-trained model to generate pseudo-labels for unlabeled data, which is then used to fine-tune the model on both labeled and pseudo-labeled data. The idea behind self-training is to leverage the vast amount of unlabeled data that is often readily available to improve the model's performance.
The Noisy Student technique is introduced to improve the performance of self-training by adding noise to the self-supervised pre-training process. The noise comes from randomly augmenting the input data during pre-training and the dropout technique during fine-tuning. By adding noise to the pre-training process, the model becomes more robust and better at generalizing to new and unseen data.
How Does Self-Training with Noisy Student Work?
The self-training with Noisy student algorithm can be divided into two phases: pre-training and fine-tuning. In the pre-training phase, a self-supervised model is trained on a large set of unlabeled data. The purpose of this phase is to learn a general representation of the data that can be used for downstream tasks. The self-supervised pre-training can be done using any self-supervised learning algorithm, such as contrastive learning, rotation prediction, or masked language modeling.

In the fine-tuning phase, the pre-trained model is fine-tuned on both labeled and pseudo-labeled data. The pseudo-labels are generated by using the pre-trained model to make predictions on the unlabeled data. These predictions are then used as if they were true labels to fine-tune the model. The noisy student technique is used to add noise to the input data during fine-tuning, which helps the model to better generalize to new and unseen data.
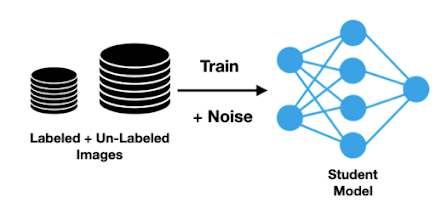
Implementing self-training with noisy student in PyTorch is straightforward. Here are the basic steps:
- Pre-train a self-supervised model on a large set of unlabeled data. You can use any self-supervised learning algorithm for this, such as contrastive learning or masked language modeling. PyTorch provides pre-trained models for some of these algorithms, such as the torchvision.models.resnet50() model for contrastive learning.
- Generate pseudo-labels for the unlabeled data using the pre-trained model. You can use the model's softmax output as the predicted labels. PyTorch provides a DataLoader class to handle loading and batching the unlabeled data.
- Combine the labeled and pseudo-labeled data to create a new training set. You can use PyTorch's ConcatDataset class to combine the datasets.
- Fine-tune the pre-trained model on the combined labeled and pseudo-labeled data. During fine-tuning, add noise to the input data using random augmentations and dropout. You can use PyTorch's transforms and nn.Dropout modules for this.
- Evaluate the fine-tuned model on a validation set to see how well it generalizes to new data.
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import ConcatDataset, DataLoader
# Define the self-supervised model for pre-training
pretrained_model = torchvision.models.resnet50(pretrained=True)
# Remove the last fully connected layer and replace it with a linear layer with 1000 output features
pretrained_model.fc = nn.Linear(2048, 1000)
# Freeze all layers except the last two
for param in pretrained_model.parameters():
param.requires_grad = False
for param in pretrained_model.fc.parameters():
param.requires_grad = True
# Define the fine-tuning model
finetuned_model = torchvision.models.resnet50(pretrained=False)
# Replace the last fully connected layer with a linear layer with 10 output features for CIFAR-10
finetuned_model.fc = nn.Linear(2048, 10)
# Combine the pre-trained and fine-tuned models
model = nn.Sequential(pretrained_model, finetuned_model)
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Define the data transforms
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Load the labeled data
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
trainloader = DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
# Load the unlabeled data
unlabeledset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
unlabeledloader = DataLoader(unlabeledset, batch_size=128, shuffle=False, num_workers=2)
# Train the model
for epoch in range(10):
running_loss = 0.0
for i, (labeled_data, labels) in enumerate(trainloader):
# Train on labeled data
optimizer.zero_grad()
outputs = model(labeled_data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# Generate pseudo-labels for unlabeled data
with torch.no_grad():
unlabeled_data = next(iter(unlabeledloader))
outputs = model(unlabeled_data)
_, pseudo_labels = torch.max(outputs, 1)
# Train on labeled and pseudo-labeled data
optimizer.zero_grad()
labeled_outputs = model(labeled_data)
unlabeled_outputs = model(unlabeled_data)
loss = criterion(labeled_outputs, labels) + criterion(unlabeled_outputs, pseudo_labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
# Evaluate the model on the test set
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))This implementation follows the basic steps of self-training with Noisy student, including the pre-training of a model on a large unlabeled dataset, the fine-tuning of the pre-trained model on a smaller labeled dataset, and the iterative training with both labeled and pseudo-labeled data.
Conclusion
Self-training with Noisy Student is a powerful semi-supervised learning technique that can significantly improve model performance using unlabeled data. By pre-training a self-supervised model and generating pseudo-labels for unlabeled data, the model can be fine-tuned on both labeled and pseudo-labeled data to better generalize to new and unseen data. Implementing self-training with noisy student in PyTorch
Comments
Post a Comment