
Contrastive learning is a type of unsupervised learning technique used in deep learning models. The primary goal of contrastive learning is to learn useful representations of data by comparing different examples in a dataset. This comparison is used to learn similarities and differences between examples and create a feature space where similar examples are clustered together. Contrastive learning has been widely used in various fields, such as computer vision, natural language processing, and speech recognition, to learn robust and discriminative features for downstream tasks.
In this blog post, we will provide an overview of contrastive learning, including its loss type, intuition, and implementation using Keras or PyTorch libraries for image classification.

Intuition
The intuition behind contrastive learning is straightforward. Given two examples, the model learns to compare their features and assign similar examples to the same point in the feature space and dissimilar examples to different points. The model learns to identify important features that are shared between similar examples and distinguish them from features that are unique to each example.For example, consider an image classification task where we want to classify different types of animals. The model can learn to identify features that are common to different animals, such as their body shape, color, and texture, and use them to classify new images. By comparing different images of the same animal and different animals, the model can learn to differentiate between similar and dissimilar examples and learn a robust feature space that separates different types of animals.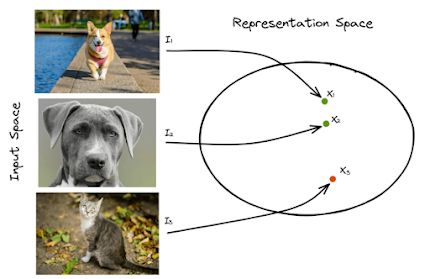
The intuition behind contrastive learning is straightforward. Given two examples, the model learns to compare their features and assign similar examples to the same point in the feature space and dissimilar examples to different points. The model learns to identify important features that are shared between similar examples and distinguish them from features that are unique to each example.
For example, consider an image classification task where we want to classify different types of animals. The model can learn to identify features that are common to different animals, such as their body shape, color, and texture, and use them to classify new images. By comparing different images of the same animal and different animals, the model can learn to differentiate between similar and dissimilar examples and learn a robust feature space that separates different types of animals.
Contrastive Loss
The main idea behind contrastive learning is to learn a representation of data by maximizing the similarity between similar examples and minimizing the similarity between dissimilar examples. The most common loss function used in contrastive learning is the contrastive loss function. This function takes two input examples and returns a scalar value representing their similarity. The contrastive loss function is defined as follows:
$L = (1-y)D^2 + y(max(m-D, 0)^2)$
Here, D is the distance between two input examples in the feature space, m is a margin hyperparameter that controls the minimum distance between two examples, and y is the label that indicates whether two examples are similar or dissimilar (y=0 for similar examples and y=1 for dissimilar examples).
The first term in the contrastive loss function penalizes similar examples that are too far apart in the feature space, while the second term penalizes dissimilar examples that are too close to each other. The margin hyperparameter m controls the minimum distance between similar and dissimilar examples, and it is used to prevent the model from learning trivial solutions that assign similar examples to the same feature space point.
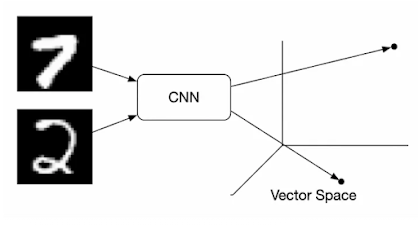
Keras Implementation of Contrastive Loss in Image Classification
In this section, we will provide an implementation of the contrastive loss function in Keras or PyTorch for image classification tasks. The implementation assumes that we have a dataset of labeled images and we want to learn a feature space that separates different classes of images.
First, we need to define a Siamese network that takes two input images and computes their features using a shared network architecture. The Siamese network is trained using the contrastive loss function to maximize the similarity between similar examples and minimize the similarity between dissimilar examples.
Here is an example implementation of a Siamese network using Keras:
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense
from keras.models import Model
# Define shared network architecture
inputs = Input(shape=(224, 224, 3))
x = Conv2D(32, (3, 3), activation='relu')(inputs)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(64, (3, 3, activation='relu')(x)
x = MaxPooling2D(pool_size=(2, 2))(x)
x = Flatten()(x)
x = Dense(128, activation='relu')(x)
shared_model = Model(inputs, x)
Define Siamese network
input_a = Input(shape=(224, 224, 3))
input_b = Input(shape=(224, 224, 3))
output_a = shared_model(input_a)
output_b = shared_model(input_b)Define distance metric
from keras import backend as K
def euclidean_distance(vects):
x, y = vects
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))Define contrastive loss function
def contrastive_loss(y_true, y_pred):
margin = 1
return K.mean(y_true * K.square(y_pred) + (1 - y_true) * K.square(K.maximum(margin - y_pred, 0)))Define final model
distance = Lambda(euclidean_distance)([output_a, output_b])
model = Model(inputs=[input_a, input_b], outputs=distance)Compile the model
model.compile(loss=contrastive_loss, optimizer='adam')
Train the model
In this example, we define a shared network architecture that consists of two convolutional layers followed by two max pooling layers and a dense layer. The shared network takes an input image of size (224, 224, 3) and outputs a feature vector of size 128.
We then define a Siamese network that takes two input images and computes their feature vectors using the shared network architecture. We also define a distance metric that computes the Euclidean distance between two feature vectors.
Next, we define the contrastive loss function that takes the label y_true indicating whether two images are similar or dissimilar and the predicted distance y_pred between their feature vectors. The contrastive loss function computes the difference between the predicted distance and the margin hyperparameter m and applies a hinge loss to penalize dissimilar examples that are too close together and similar examples that are too far apart.
Finally, we define the final model that takes two input images and computes their distance using the distance metric and the Siamese network. We compile the model using the contrastive loss function and the Adam optimizer.
To train the model, we need to prepare the data in the form of pairs of similar and dissimilar examples. We can use the Keras `ImageDataGenerator` class to generate batches of augmented images and then create pairs of similar and dissimilar images using the following function:
def create_pairs(x, y, num_classes):
"""Create pairs of similar and dissimilar images"""
pairs = []
labels = []
n = min([len(y[y == i]) for i in range(num_classes)]) - 1
for i in range(num_classes):
for j in range(n):
idx1 = np.where(y == i)[0][j]
idx2 = np.where(y == i)[0][j+1]
pairs.append([x[idx1], x[idx2]])
labels.append(0)
idx1 = np.where(y != i)[0][j]
idx2 = np.random.randint(0, len(x) - 1)
pairs.append([x[idx1], x[idx2]])
labels.append(1)
return np.array(pairs), np.array(labels)In this function, we create pairs of similar and dissimilar images by selecting two images with the same label and two images with different labels. We then train the model using the following code:
history = model.fit([x_train[:, 0], x_train[:, 1]], y_train, validation_split=0.2, batch_size=64, epochs=10)
Evaluate the model
y_pred = model.predict([x_test[:, 0], x_test[:, 1]])
y_pred[y_pred <= 0.5] = 0
y_pred[y_pred > 0.5] = 1
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: {:.2f}%".format(accuracy * 100))
In this code, we train the model using the `fit` method and validate it on a validation set using 20% of the training data. We use a batch size of 64 and train the model for 10 epochs. After training, we evaluate the model on a test set and compute the accuracy using scikit-learn's `accuracy_score` function.
Conclusion
Contrastive learning is a powerful technique for learning representations that can be used in a variety of machine-learning tasks, including image classification, object detection, and natural language processing. By learning to distinguish between similar and dissimilar examples, contrastive learning can learn representations that capture the underlying structure of the data and generalize to unseen examples.
In this blog post, we introduced contrastive learning and discussed the intuition behind the contrastive loss function. We also provided a Keras implementation of the contrastive loss function for image classification and showed how to train a Siamese network using pairs of similar and dissimilar images.
Comments
Post a Comment