
Facebook video classification team has recently released a new video classification model called TimeSformer, in a paper titled: Is Space-Time Attention All You Need for Video Understanding?, which promises to outperform previous models while being more computationally efficient. In this blog post, we'll take a closer look at TimeSformer and how to train it on a custom video dataset using PyTorch.
What is TimeSformer?
TimeSformer is a neural network architecture for video classification. It is based on the Transformer architecture, which has been highly successful in natural language processing tasks. However, while the original Transformer was designed for sequential data, TimeSformer is designed for video data, which has both temporal and spatial dimensions.
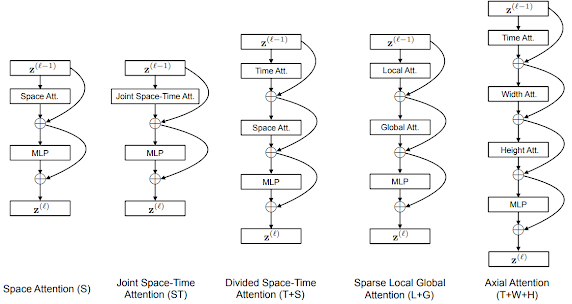
https://arxiv.org/pdf/2102.05095v4.pdf
TimeSformer achieves this by applying the self-attention mechanism of the Transformer architecture across both time and space. This allows the model to learn dependencies between frames and between different parts of the image. TimeSformer also uses a feature pyramid to encode information at multiple spatial resolutions, which allows the model to capture both fine-grained and coarse-grained information.

Training TimeSformer on a Custom Video Dataset
To train TimeSformer on a custom video dataset, we'll use PyTorch, a popular deep-learning library. Here are the steps we'll follow:
1. Preprocess the video data: Before we can train TimeSformer on our video dataset, we need to preprocess the data into a format that the model can use. We'll use FFmpeg, a powerful video processing tool, to extract frames from the videos and save them as image files.
ffmpeg -i video.mp4 -vf fps=30 frames/frame%04d.png
This command extracts frames from the video "video.mp4" at a frame rate of 30 frames per second and saves them as image files in the "frames" directory.
2. Create a PyTorch dataset: Next, we'll create a PyTorch dataset class to load the preprocessed video data. The dataset class should return a tuple of frames and labels for each video:
import os
import glob
import torch
from torchvision.io import read_image
class VideoDataset(torch.utils.data.Dataset):
def __init__(self, root_dir):
self.root_dir = root_dir
self.video_paths = glob.glob(os.path.join(root_dir, '*.mp4'))
self.label_map = {'class1': 0, 'class2': 1, 'class3': 2}
def __len__(self):
return len(self.video_paths)
def __getitem__(self, idx):
video_path = self.video_paths[idx]
frames = []
for frame_path in sorted(glob.glob(os.path.join(video_path, '*.png'))):
frame = read_image(frame_path)
frames.append(frame)
frames = torch.stack(frames)
label = self.label_map[os.path.basename(video_path).split('_')[0]]
return frames, labelThis dataset class loads all videos in a directory and maps the class names to integer labels.
3. Define the TimeSformer model: We'll use the TimeSformer model implemented in Facebook's official repository. Here's how to define the model:
import torch
from torch import nn
from timesformer.models.video_transformer import TimeSformer
class VideoClassifier(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.timesformer = TimeSformer(
dim = 512,
depth = 12,
heads = 8,
clip_len = 16,
num_classes = num_classes
)
def forward(self, x):
return self.timesformer(x)This model class wraps the TimeSformer model and adds a fully connected layer at the end to produce the output probabilities.
4. Split the dataset into training and validation sets: We'll use PyTorch's 'SubsetRandomSampler' to split the dataset into training and validation sets. This sampler randomly samples elements from a given list of indices, which we'll use to split the dataset.
from torch.utils.data import DataLoader, SubsetRandomSampler
dataset = VideoDataset('path/to/dataset')
train_indices = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # example train indices
val_indices = [10, 11, 12, 13, 14] # example val indices
train_sampler = SubsetRandomSampler(train_indices)
val_sampler = SubsetRandomSampler(val_indices)
train_loader = DataLoader(dataset, batch_size=2, sampler=train_sampler)
val_loader = DataLoader(dataset, batch_size=2, sampler=val_sampler)This code creates two data loaders for the training and validation sets using the SubsetRandomSampler.
5. Define the loss function and optimizer: We'll use cross-entropy loss and the Adam optimizer to train the model.
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)6. Train the model: Finally, we can train the model using a loop that iterates over the batches in the training data loader, computes the loss and gradients, and updates the model parameters.
num_epochs = 10
for epoch in range(num_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# Evaluate on validation set
correct = 0
total = 0
with torch.no_grad():
for data in val_loader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_acc = 100 * correct / total
print('[%d] loss: %.3f, val_acc: %.3f' %
(epoch + 1, running_loss / len(train_loader), val_acc))This code trains the model for 10 epochs and evaluates the model on the validation set after each epoch. We print the average training loss and validation accuracy for each epoch.
Wrapping up
In this blog post, we've looked at Facebook's video classification TimeSformer model and how to train it on a custom video dataset using PyTorch. We've covered the necessary steps, including data preprocessing, creating a PyTorch dataset, defining the model, splitting the dataset into training and validation sets, defining the loss function and optimizer, and training the model. With this knowledge, you should be able to apply TimeSformer to your own video classification tasks.
Comments
Post a Comment