
If you're interested in the latest advances in deep learning for computer vision, you may have heard about DeiT, or the Data-efficient Image Transformer. DeiT is a state-of-the-art model for image classification that achieves impressive accuracy while using fewer training samples than its predecessors. In this blog post, we'll take a closer look at DeiT and how you can implement and fine-tune it in TensorFlow.
What is DeiT?
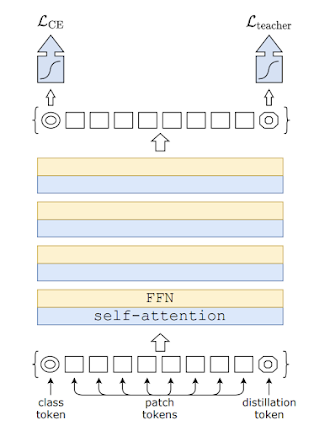
DeiT is a model developed by researchers at META AI that builds on the success of the Transformer architecture, which was originally developed for natural language processing tasks. Like the Transformer, DeiT uses self-attention to process input data, allowing it to capture complex relationships between image features. However, DeiT is specifically designed for image classification tasks, and achieves this by using a novel distillation-based training method that enables it to be trained on smaller datasets than previous models.
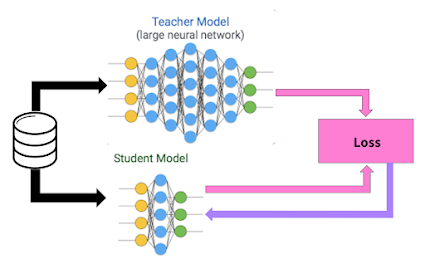
The key innovation behind DeiT is the use of distillation through attention. This involves training a smaller "student" model to mimic the behavior of a larger "teacher" model by paying attention to the same parts of the input. The student model is then fine-tuned on a smaller dataset and can achieve similar accuracy to the teacher model while using far fewer training samples. In the case of DeiT, the teacher model is a much larger model that is pre-trained on a large dataset, while the student model is trained using distillation on a smaller dataset.
How to Implement DeiT in TensorFlow
Implementing DeiT in TensorFlow is relatively straightforward, thanks to the availability of open-source implementations from Facebook AI and the TensorFlow community. Here are the steps you can follow to implement and fine-tune DeiT in TensorFlow:
- Install the necessary packages and dependencies, including TensorFlow, the TensorFlow model garden, and the PyTorch Lightning framework.
- Download the DeiT model weights and configuration files from the official GitHub repository, or use the pre-trained models available in the TensorFlow model garden.
- Load the model into TensorFlow using the appropriate API, depending on the model format.
- Fine-tune the model on your own dataset using transfer learning techniques, such as freezing the early layers of the model and training only the later layers.
- Evaluate the performance of the model on your test set, and adjust the hyperparameters as needed to achieve optimal accuracy.
By following these steps, you can easily implement and fine-tune DeiT in TensorFlow for your own image classification tasks.
Keras Implementation of DeiT
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_accuracy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
from tensorflow.keras.applications import EfficientNetB7
from tensorflow.keras.models import Model
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
# Load the DeiT model architecture and weights
deit = tf.keras.models.load_model('deit_model.h5')
# Freeze the first few layers of the model
for layer in deit.layers[:-10]:
layer.trainable = False
# Add a new dense layer for classification
x = deit.layers[-2].output
predictions = Dense(3, activation='softmax')(x)
model = Model(inputs=deit.input, outputs=predictions)
# Compile the model with an appropriate optimizer and loss function
model.compile(optimizer=Adam(lr=0.001),
loss='categorical_crossentropy',
metrics=[categorical_accuracy])
# Prepare the data for training and validation
train_data_dir = 'train_data'
validation_data_dir = 'validation_data'
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
# Define callbacks for saving the best model and early stopping
filepath = "best_model.h5"
checkpoint = ModelCheckpoint(filepath, monitor='val_categorical_accuracy', verbose=1,
save_best_only=True, mode='max')
early_stop = EarlyStopping(monitor='val_categorical_accuracy', patience=5, mode='max')
# Train the model on the data and validate
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // train_generator.batch_size,
epochs=20,
validation_data=validation_generator,
validation_steps=validation_generator.samples // validation_generator.batch_size,
callbacks=[checkpoint, early_stop])
# Evaluate the model on a test set
test_data_dir = 'test_data'
test_datagen = ImageDataGenerator(rescale=1. / 255)
test_generator = test_datagen.flow_from_directory(
test_data_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
model.load_weights('best_model.h5')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=test_generator.samples // test_generator.batch_size)
print('Test accuracy:', test_acc)
# Plot the training and validation loss and accuracy
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
plt.plot(history.history['categorical_accuracy'])
plt.plot(history.history['val_categorical_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
Comments
Post a Comment