
In the field of Natural Language Processing (NLP), the use of word and sentence embeddings has revolutionized the way we analyze and understand language. Word embeddings and sentence embeddings are numerical representations of words and sentences, respectively, that capture the underlying semantics and meaning of the text.
In this blog post, we will discuss what word and sentence embeddings are, how they are created, and how they can be used in NLP tasks. We will also provide some Python code examples to illustrate the concepts.
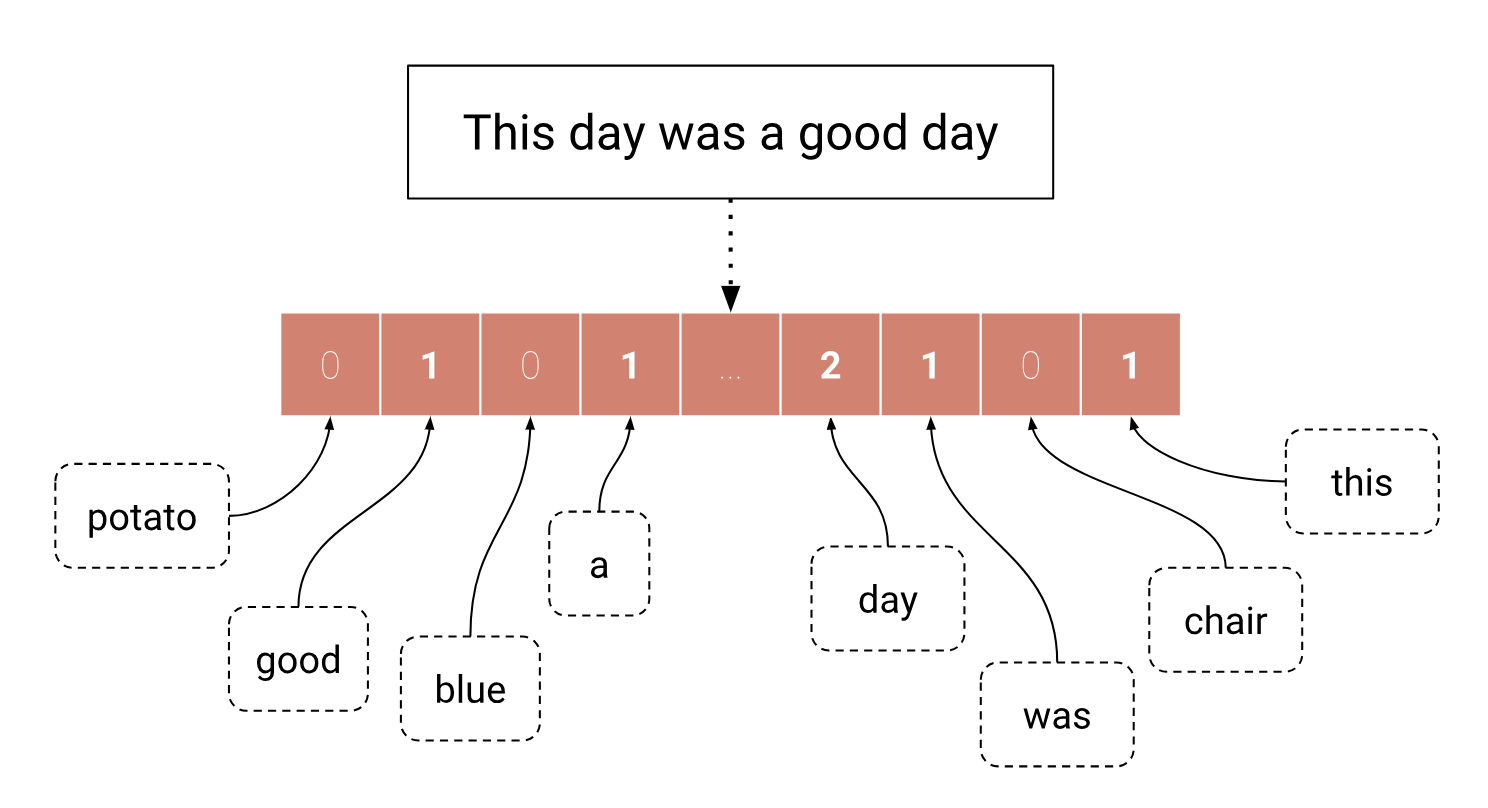
Word Embeddings:
A word embedding is a way of representing words as high-dimensional vectors. These vectors capture the meaning of a word based on its context in a given text corpus. The most commonly used approach to creating word embeddings is through the use of neural networks, particularly the Word2Vec algorithm.
The Word2Vec algorithm is a neural network model that learns word embeddings by predicting the context in which a word appears. The model takes a large corpus of text as input and creates a vector representation for each word in the vocabulary. The idea behind the model is that words that appear in similar contexts tend to have similar meanings.
In Python, we can use the Gensim library to create word embeddings using the Word2Vec algorithm. Here is an example code snippet:
from gensim.models import Word2Vec
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model = Word2Vec(sentences, min_count=1)
print(model["cat"])In this example, we first import the Word2Vec class from the Gensim library. We then create a list of two sentences, each containing three words. We pass this list to the Word2Vec constructor, along with the parameter min_count=1, which specifies that any word that appears less than once in the corpus should be ignored. Finally, we print the vector representation of the word "cat" using the model["cat"] syntax.
Sentence Embeddings:
A sentence embedding is a numerical representation of a sentence that captures its meaning and context. Unlike word embeddings, which represent individual words, sentence embeddings represent entire sentences.
One popular approach to creating sentence embeddings is through the use of pre-trained models, such as the Universal Sentence Encoder (USE) from Google. The USE model is a deep learning model that has been pre-trained on a large corpus of text data, and can be used to encode sentences into high-dimensional vector representations.
import tensorflow_hub as hub
import tensorflow_text
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
sentences = ["This is an example sentence.", "Here is another sentence."]
embeddings = embed(sentences)
print(embeddings)In this example, we first import the TensorFlow Hub library, which allows us to load pre-trained models from the internet. We then load the USE model by passing its URL to the hub.load() function. We create a list of two example sentences and pass it to the embed() function of the USE model to obtain the sentence embeddings. Finally, we print the resulting embeddings.
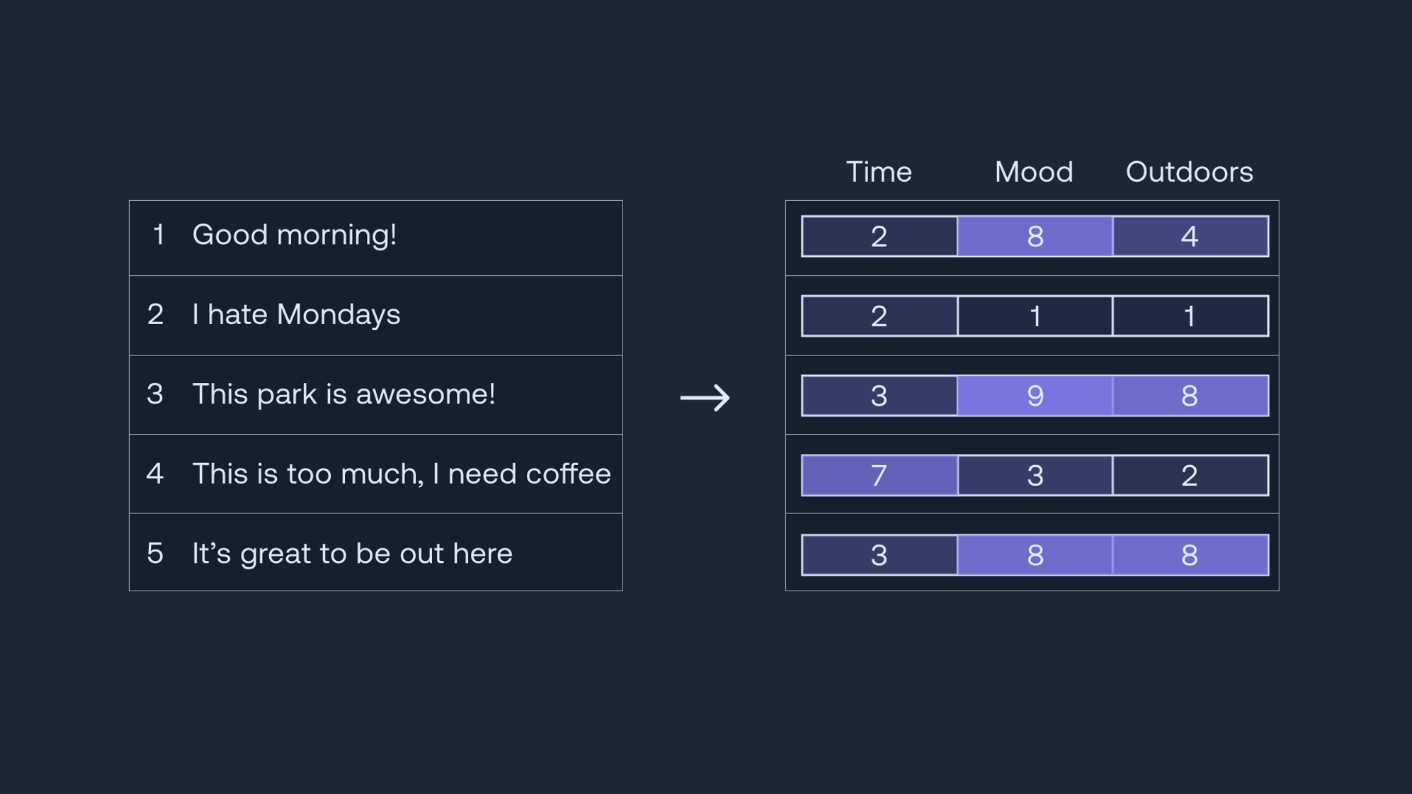
Applications of Word and Sentence Embeddings:
Word and sentence embeddings have many applications in NLP, such as text classification, named entity recognition, sentiment analysis, and machine translation. Here are some examples of how these embeddings can be used in practice:
Text classification: Word embeddings can be used to represent the words in a text document and then fed into a classification model, such as logistic regression or a support vector machine (SVM). The resulting model can then be used to classify new documents based on their content. Sentence embeddings can also be used in text classification by representing entire sentences as high-dimensional vectors and then feeding them into a classifier.
Here is an example code snippet using word embeddings for text classification:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
# Load the 20 newsgroups dataset
newsgroups_train = fetch_20newsgroups(subset='train')
# Convert the text data into word embeddings using Word2Vec
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(newsgroups_train.data)
model = LogisticRegression().fit(X, newsgroups_train.target)
# Use the model to classify new documents
newsgroups_test = fetch_20newsgroups(subset='test')
X_test = vectorizer.transform(newsgroups_test.data)
predicted = model.predict(X_test)In this example, we first load the 20 newsgroups dataset using the fetch_20newsgroups() function from scikit-learn. We then use the CountVectorizer() class to convert the text data into word embeddings. We train a logistic regression model on the resulting word embeddings, and then use the model to classify new documents from the test set.
Named entity recognition: Word embeddings can be used to identify named entities in text, such as people, organizations, and locations. This can be done by training a named entity recognition model on a corpus of text that has been annotated with entity labels.
Here is an example code snippet using word embeddings for named entity recognition:
import spacy
# Load the pre-trained word embeddings from spacy
nlp = spacy.load("en_core_web_md")
# Define a sample text containing named entities
text = "Barack Obama was the 44th President of the United States."
# Use spacy to identify the named entities in the text
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)In this example, we first load the pre-trained word embeddings from the spacy library using the spacy.load() function. We define a sample text containing a named entity, and then use spacy to identify the named entity using the doc.ents property.
Sentiment analysis: Sentence embeddings can be used to analyze the sentiment of a piece of text, such as whether it is positive or negative. This can be done by training a sentiment analysis model on a corpus of text that has been labeled with sentiment scores.
Here is an example code snippet using sentence embeddings for sentiment analysis:
import pandas as pd
import tensorflow_hub as hub
# Load the pre-trained Universal Sentence Encoder model
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-large/5")
# Load a dataset containing movie reviews and sentiment scores
df = pd.read_csv("movie_reviews.csv")
# Use the USE model to encode the movie reviews into sentence embeddings
embeddings = embed(df["review"].tolist())
# Train a linear regression model on the sentence embeddings and sentiment scores
model = LinearRegression().fit(embeddings, df["sentiment"])
# Use the model to predict the sentiment of new movie reviews
new_reviews = ["This movie was great!", "I didn't like this movie."]
new_embeddings = embed(new_reviews)
predicted = model.predict(new_embeddings)In this example, we first load the pre-trained Universal Sentence Encoder model from TensorFlow Hub using the hub.load() function. We load a dataset containing movie reviews and sentiment scores and use the USE model to encode the movie reviews into sentence embeddings. We then train a linear regression model on the sentence embeddings and sentiment scores and use the model to predict the sentiment of new movie reviews.
Challenges and Limitations of Word and Sentence Embeddings
While word and sentence embeddings have shown great promise in a wide range of natural language processing tasks, there are still several challenges and limitations that researchers and practitioners need to be aware of. Some of these challenges include:
Polysemy and homonymy: One of the biggest challenges with word embeddings is dealing with polysemy and homonymy, which refers to words that have multiple meanings. For example, the word "bank" can refer to a financial institution or the side of a river. Word embeddings often struggle to capture these different meanings, which can lead to errors in downstream applications.
Context-dependency: Another challenge with word embeddings is that they are often highly dependent on the context in which they are used. For example, the word "mouse" can refer to a computer peripheral or a small mammal, depending on the context. This can make it difficult for word embeddings to capture the true meaning of a word.
Data bias: Another challenge with word embeddings is that they can be biased by the data they are trained on. For example, if the training data contains a lot of examples of men in leadership positions, the resulting embeddings may associate words like "CEO" and "manager" with male gender. This can lead to biased results in downstream applications.
Lack of interpretability: While word embeddings can be very effective in a wide range of NLP tasks, they are often difficult to interpret. It can be hard to understand why certain words are grouped together in the embedding space or why certain directions in the embedding space correspond to particular semantic or syntactic concepts.
Conclusion
Word and sentence embeddings have revolutionized the field of natural language processing, enabling researchers and practitioners to tackle a wide range of tasks with unprecedented accuracy and efficiency. While there are still challenges and limitations to be addressed, word and sentence embeddings have already had a profound impact on how we analyze, understand, and interact with language.
In this blog post, we have explored some of the key concepts and applications of word and sentence embeddings, and provided code examples to illustrate how they can be used in practice. We hope that this post has provided you with a solid foundation for understanding this important topic, and that you are now ready to start exploring the world of word and sentence embeddings on your own.
Code snippets:
Here are the code snippets again for reference:
Word embeddings for text classification:
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
# Load the 20 newsgroups dataset
newsgroups_train = fetch_20newsgroups(subset='train')
# Convert the text data into word embeddings using Word2Vec
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(newsgroups_train.data)
model = LogisticRegression().fit(X, newsgroups_train.target)
# Use the model to classify new documents
newsgroups_test = fetch_20newsgroups(subset='test')
X_test = vectorizer.transform(newsgroups_test.data)
predicted = model.predict(X_test)
Word embeddings for named entity recognition:
import spacy
# Load the pre-trained word embeddings from spacy
nlp = spacy.load("en_core_web_md")
# Define a sample text containing named entities
text = "Barack Obama was the 44th President of the United States."
# Use spacy to identify the named entities in the text
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)Sentence embeddings for sentiment analysis:
import transformers
import torch
# Load the pre-trained sentence embedding model
model_name = 'bert-base-uncased'
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
model = transformers.AutoModel.from_pretrained(model_name)
# Define a function to compute the sentence embedding
def get_sentence_embedding(sentence):
input_ids = torch.tensor(tokenizer.encode(sentence)).unsqueeze(0)
with torch.no_grad():
output = model(input_ids)
embeddings = output.last_hidden_state.mean(dim=1).squeeze()
return embeddings.numpy()
# Load a dataset of movie reviews
reviews = pd.read_csv('movie_reviews.csv')
# Compute the sentence embeddings for each review
embeddings = [get_sentence_embedding(review) for review in reviews['text']]
# Train a logistic regression model to predict the sentiment score
X = pd.DataFrame(embeddings)
y = reviews['sentiment']
model = LogisticRegression().fit(X, y)
# Use the model to predict the sentiment of new reviews
new_reviews = ['This movie was great!', 'This movie was terrible!']
new_embeddings = [get_sentence_embedding(review) for review in new_reviews]
X_new = pd.DataFrame(new_embeddings)
predicted = model.predict(X_new)
print(predicted)In this example, we used the BERT model to compute sentence embeddings for a dataset of movie reviews, and then trained a logistic regression model to predict the sentiment score of each review. We then used the same model to predict the sentiment score of two new reviews.
Overall, this blog post has provided an overview of word and sentence embeddings, including their applications, challenges, and limitations. We have also provided code examples to illustrate how these techniques can be used in practice. We hope that this post has been informative and useful, and that you are now equipped to explore this exciting field further on your own.
Comments
Post a Comment