
A common machine learning technique called reinforcement learning (RL) teaches an agent how to choose actions that will maximize a reward signal. By getting rewarded for activities that produce desirable results, the agent learns from its environment.
The reward signal, however, may not be clear in many real-world situations or may be challenging to get. In these circumstances, human feedback can provide the agent the direction it needs to learn effectively. Reinforcement Learning with Human Feedback is what this is (RLHF).
In this article, we'll look at how to use Python to implement a reinforcement learning algorithm with human feedback. We'll simulate a learning challenge using the OpenAI Gym environment, and we'll construct the reinforcement learning method using the Tensorforce library.
The reward signal, however, may not be clear in many real-world situations or may be challenging to get. In these circumstances, human feedback can provide the agent the direction it needs to learn effectively. Reinforcement Learning with Human Feedback is what this is (RLHF).
In this article, we'll look at how to use Python to implement a reinforcement learning algorithm with human feedback. We'll simulate a learning challenge using the OpenAI Gym environment, and we'll construct the reinforcement learning method using the Tensorforce library.
Introduction to Reinforcement Learning (RL)
The goal of Reinforcement Learning (RL), a particular approach to machine learning, is to teach an agent how to make decisions in the real world so as to maximize a reward signal. By acting and being rewarded for the results of those activities, the agent engages with the environment. The agent gains knowledge from its experiences through time, enhancing its decision-making process and maximizing reward.
RL has been applied in a variety of industries, including robotics, gaming, and finance, to mention a few. It has demonstrated success in resolving challenging issues when conventional supervised and unsupervised learning approaches might not be practical.
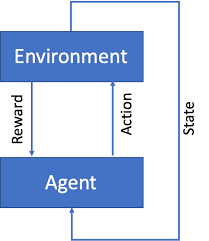
How to Implement RLHF in Python
To implement RLHF, we'll use the Cartpole environment, in which balancing a pole attached to a rolling cart is the objective. Moving the trolley either to the left or to the right are the agent's two options.
The first step is to install the required libraries, OpenAI Gym and Tensorforce. You can do this by running the following commands in your terminal:
The first step is to install the required libraries, OpenAI Gym and Tensorforce. You can do this by running the following commands in your terminal:
pip install gym
pip install tensorforceWe'll then create a function to request input from people. This function will show the environment's current status and prompt the user for a reward for the agent's action.
def ask_feedback(state, action):
print("Current state: ", state)
print("Action taken by agent: ", action)
reward = float(input("Please provide a reward for this action (0-1): "))
return rewardNow, we'll create the reinforcement learning agent using Tensorforce. The agent will be a deep neural network with two hidden layers, and will use the Adam optimizer for training.
import tensorforce
agent = tensorforce.Agent.create(
agent='tensorforce',
environment='gym',
states=dict(type='float', shape=(4,)),
actions=dict(type='int', num_actions=2),
network=[
dict(type='dense', size=32),
dict(type='dense', size=32)
],
optimizer=dict(type='adam', learning_rate=1e-3)
)The reinforcement learning algorithm will then be executed, with each stage requiring human input. The feedback will be interpreted by the agent as a reward signal, and it will adjust its policy accordingly.
import gym
env = gym.make("CartPole-v0")
state = env.reset()
while True:
actions = agent.act(state)
next_state, reward, done, _ = env.step(actions)
reward = ask_feedback(state, actions)
agent.observe(reward=reward, terminal=done)
state = next_state
if done:
state = env.reset()That's all, then! We've successfully constructed a Python reinforcement learning algorithm with human feedback in just a few lines of code. Incorporating human feedback will help our agents perform better and be better equipped to handle challenging problems.
When it comes to RLHF, this is merely the top of the iceberg. There are other further methods.
Comments
Post a Comment