
Generative Pre-trained Transformer 3 (GPT-3) is a language model that uses deep learning to produce text that resembles human speech (output). It may also generate code, stories, poems, and other types of content in addition to text. It has become such a hot topic in the field of natural language processing due to these capabilities and factors (NLP- - an essential sub-branch of data science).
In May 2020, Open AI released GPT-3 as the replacement for GPT-2, their prior language model (LM). It is regarded as being bigger and superior to GPT-2. In fact, when compared to other language models, the final version of OpenAI GPT-3 has roughly 175 billion trainable parameters, making it the largest model learned to date. This 72-page research paper provides a thorough explanation of the characteristics and capabilities.

What Are Language Models (LLMs)!
Language models are essentially statistical techniques for predicting the subsequent word or words in a sequence. Language models are, in other words, a probability distribution over a list of words. Language model applications include the following:
- Part of Speech (PoS) Tagging
- Machine Translation
- Text Classification
- Speech Recognition
- Information Retrieval
- News Article Generation
- Question Answering, etc.
GPT-3 Model Architecture
The GPT-3 is a family of models rather than a single model. The amount of trainable parameters varies between members of the same family of models. Each model, architecture, and its accompanying parameters are shown in the following table:
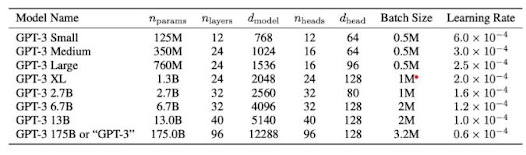
The OpenAI GPT-3 family of models, which uses alternate dense and sparse attention patterns, is really based on the same transformer-based architecture as the GPT-2 model, including the changed initialization, pre-normalization, and reverse tokenization.
The largest version of GPT-3, often known as "GPT-3," has 3.2 M batch size, 96 attention layers, and 175 B parameters.
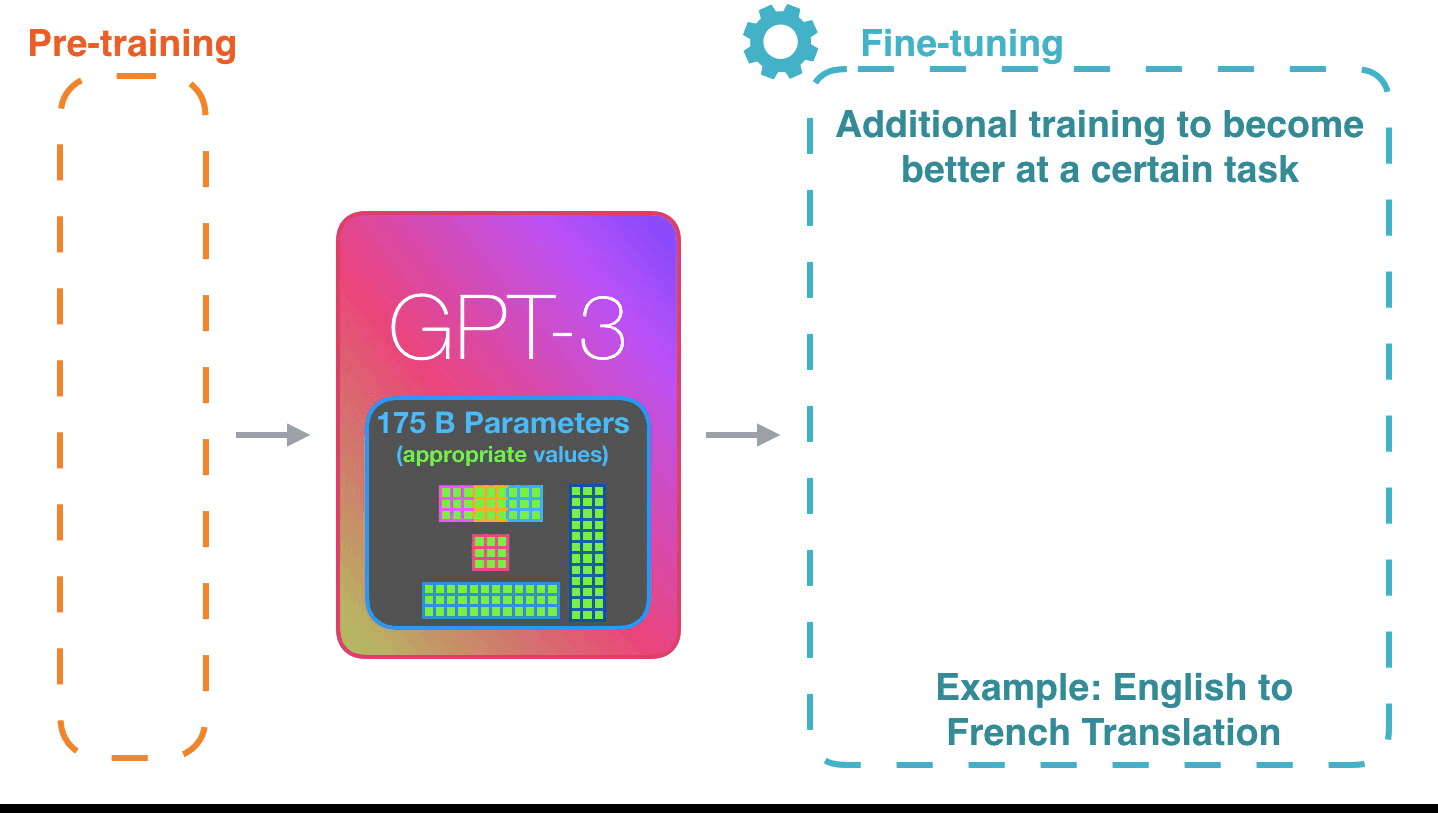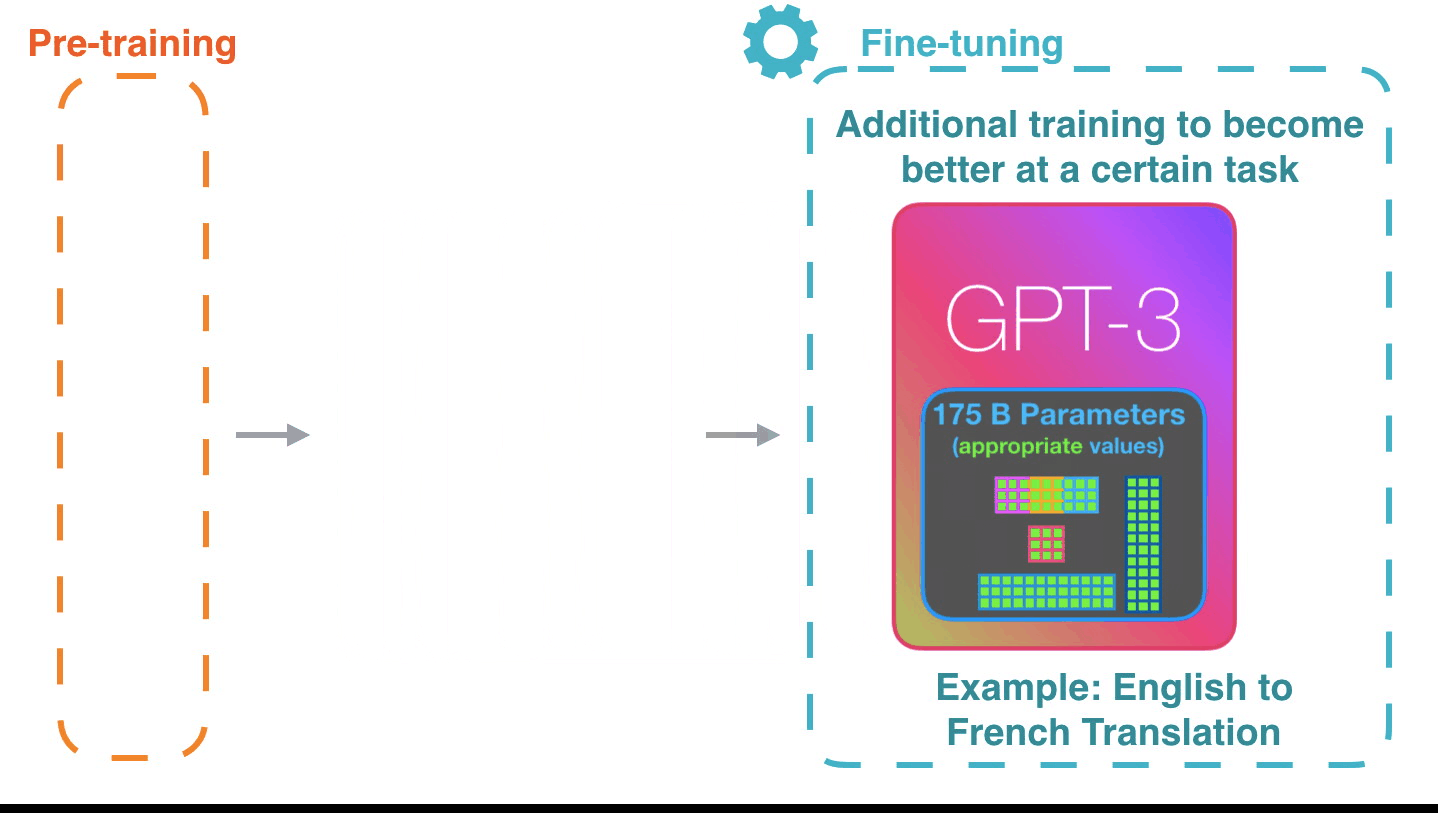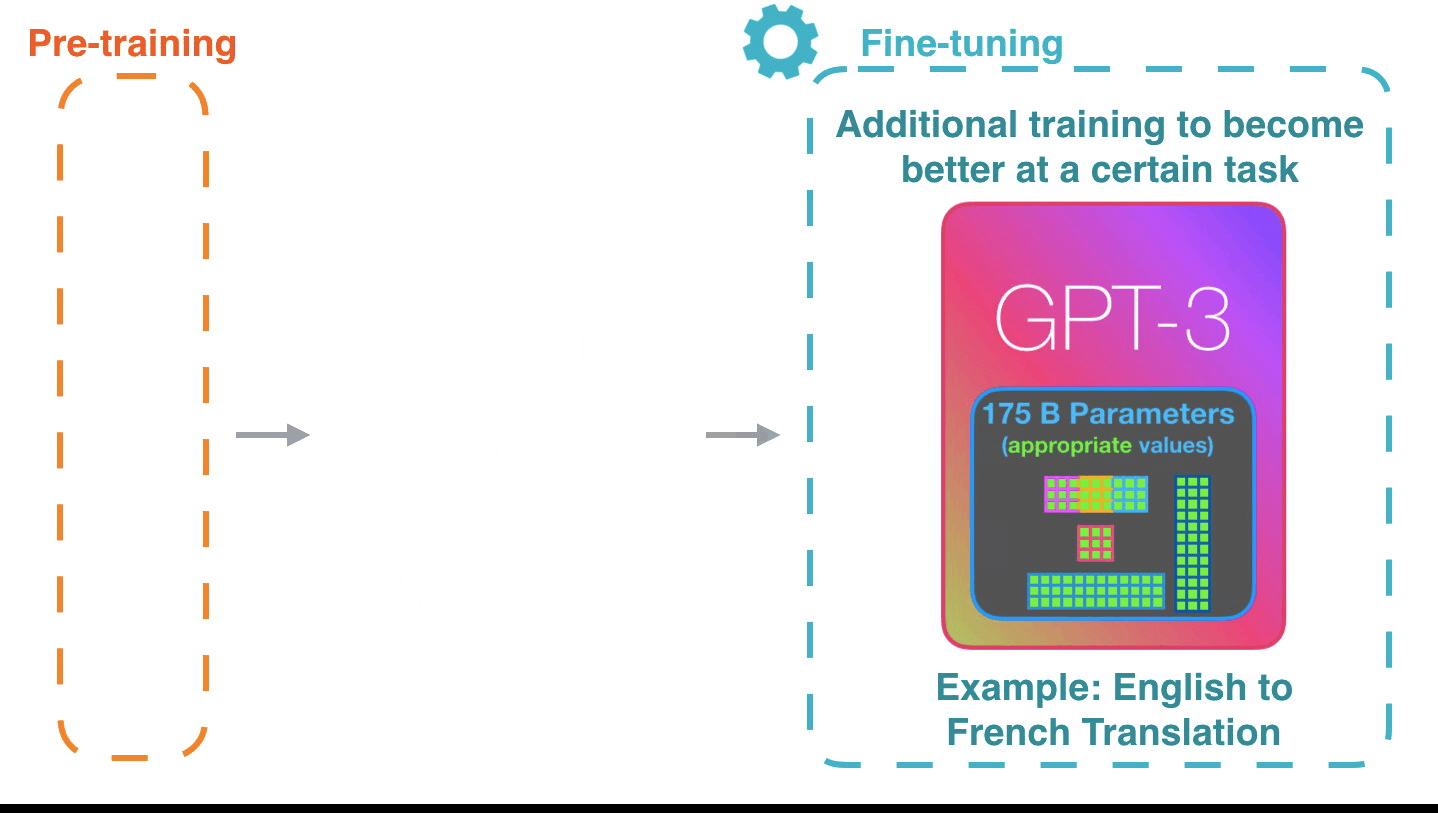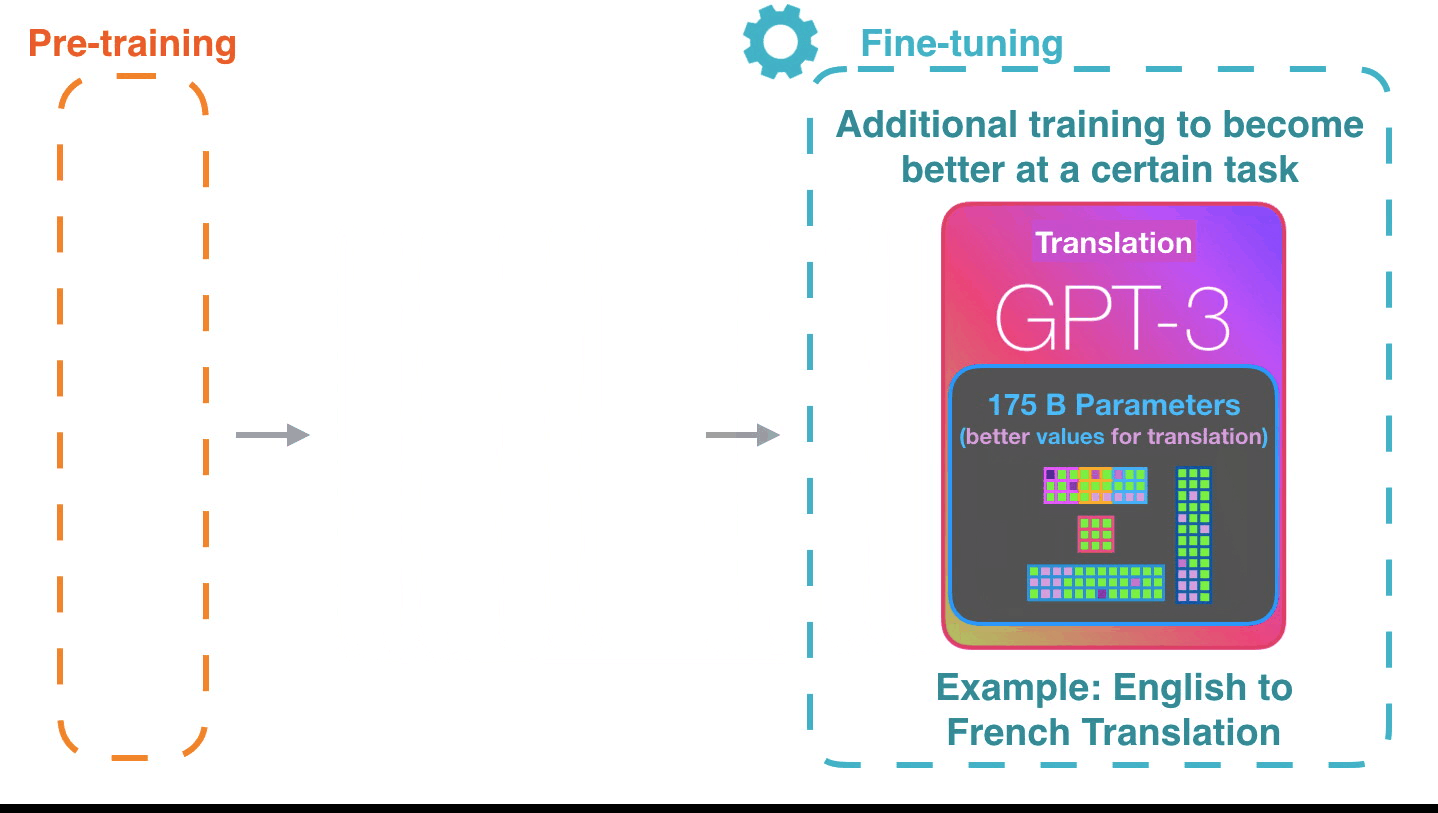
Fine-Tuning GPT-3
Fine-tuning GPT-3 using Python involves using the GPT-3 API to access the model, and Python's libraries and tools to preprocess data and train the model on a specific task. Here are the general steps you would follow to fine-tune GPT-3 for a keyword classification task:
- Sign up for an API key from OpenAI to access the GPT-3 API.
- Install the OpenAI API client and any other required Python libraries, such as transformers, torch, and pandas.
- Use the API client to retrieve the GPT-3 model from the API and load it into your Python script.
- Preprocess your training data by dividing it into input and output pairs, and formatting it into the appropriate format for the GPT-3 model. You may also want to split your data into training and validation sets.
- Train the model by looping through your training data and using the GPT-3 model to predict the keywords for each input, updating the model's weights based on the prediction error. You can use techniques such as backpropagation and stochastic gradient descent to optimize the model's performance.
- Test the model on your validation data to see how well it performs on unseen examples.
- If the model's performance is not satisfactory, you may need to adjust your training hyperparameters, such as the learning rate or the batch size, and retrain the model.
How to Fine-Tune GPT-3 in Pytorch
Here's some example code that demonstrates each of the steps I listed for fine-tuning GPT-3 using Python for a keyword classification task:
1. Sign up for an API key from OpenAI and install the API client:
!pip install openai
import openai
openai.api_key = "YOUR_API_KEY"¨2. Install any required libraries:
!pip install transformers pandas torch
import transformers
import pandas as pd
import torch3. Retrieve and load the GPT-3 model, The correct way to load the 'GPT-3' model into your Python script is to use the transformers library, like this:
import openai
import transformers
# Replace YOUR_API_KEY with your actual API key
openai.api_key = "YOUR_API_KEY"
# Set the model engine (e.g. "text-davinci-002")
model_engine = "text-davinci-002"
# Use the OpenAI API to retrieve the model
model = openai.Model.retrieve(model_engine)
# Load the model into your Python script using the transformers library.
gpt3_model = transformers.GPT2Tokenizer.from_pretrained(model.model_id)This code will retrieve the specified 'GPT-3' model from the OpenAI API and load it into your Python script as an instance of the transformers.'GPT2Tokenizer' class. You can then use the 'gpt3_model' object to fine-tune the model for your classification task.
In the context of the OpenAI API and the transformers library, 'model.model_id' is a string that specifies the identifier of the 'GPT-3' model being used. The model_id is used to retrieve the model from the OpenAI API and to specify which version of the 'GPT-3' model you want to use. The model_engine variable specifies the identifier of the 'GPT-3' model you want to use (in this case, "text-davinci-002"), and the model.model_id expression retrieves the model_id of the model as a string. The transformers.'GPT2Tokenizer.from_pretrained()' function then uses this 'model_id' to load the specified 'GPT-3' model into your Python script.
4. Preprocess the training data:
# Read in your training data as a pandas DataFrame
df = pd.read_csv("train.csv")
# Split the data into input and output pairs
X_train = df["input"].values
y_train = df["keywords"].values
# Convert the input and output pairs to the format required by the GPT-3 model
X_train = [{"prompt": x, "max_tokens": 2048} for x in X_train]
y_train = [{"keywords": y} for y in y_train]
# Split the data into a training and validation set
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.2)5. Train the model
# Set the training hyperparameters
batch_size = 32
learning_rate = 0.001
num_epochs = 10
# Create a PyTorch dataloader from the training data
train_dataloader = torch.utils.data.DataLoader(
list(zip(X_train, y_train)), batch_size=batch_size, shuffle=True
)
# Loop through the training data for the specified number of epochs
for epoch in range(num_epochs):
for i, (inputs, targets) in enumerate(train_dataloader):
# Use the GPT-3 model to make predictions for the input
outputs = model.predict(inputs)
# Calculate the prediction error
loss = calculate_loss(outputs, targets)
# Use backpropagation and SGD to update the model weights
loss.backward()
optimizer.step()
# Print the training progress
print(f"Epoch {epoch+1}/{num_epochs}, step {i+1}/{len(train_dataloader)}, loss = {loss.item():.4f}")6. Test the model on the validation data:
# Create a PyTorch dataloader from the validation data
valid_dataloader = torch.utils.data.DataLoader(
list(zip(X_valid, y_valid)), batch_size=batch_size, shuffle=False
)
# Loop through the validation data
for inputs, targets in valid_dataloader:
# Use the GPT-3 model to make predictions for the input
outputs = model.predict(inputs)
# Calculate the prediction error
loss = calculate_loss(outputs, targets)
# Print the validation progress and loss
print(f"Validation step {i+1}/{len(valid_dataloader)}, loss = {loss.item():.4f}")7. Adjust the training hyperparameters and retrain the model if necessary:
# If the model's performance is not satisfactory, try adjusting the hyperparameters
batch_size = 64 # Increase the batch size
learning_rate = 0.002 # Increase the learning rate
# Create a new optimizer with the new learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Create a new PyTorch dataloader with the updated batch size
train_dataloader = torch.utils.data.DataLoader(
list(zip(X_train, y_train)), batch_size=batch_size, shuffle=True
)
# Retrain the model with the adjusted hyperparameters
for epoch in range(num_epochs):
for i, (inputs, targets) in enumerate(train_dataloader):
outputs = model.predict(inputs)
loss = calculate_loss(outputs, targets)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}/{num_epochs}, step {i+1}/{len(train_dataloader)}, loss = {loss.item():.4f}")Related Books

Learning Deep Learning: Theory and Practice of Neural Networks, Computer Vision, Natural Language Processing, and Transformers Using TensorFlow 1st Edition

Transformers for Natural Language Processing: Build, train, and fine-tune deep neural network architectures for NLP with Python, PyTorch, TensorFlow, BERT, and GPT-3, 2nd Edition 2nd ed. Edition
Comments
Post a Comment