
BERT stands for "Bidirectional Encoder Representations from Transformers". It is a pre-trained language model developed by Google that has been trained on a large corpus of text data to understand the contextual relationships between words (or sub-words) in a sentence. BERT has proven to be highly effective for various natural languages processing tasks such as question answering, sentiment analysis, and text classification.
The primary technological advancement of BERT is the application of Transformer's bidirectional training, a well-liked attention model, to language modeling. In contrast, earlier research looked at text sequences from either a left-to-right or a combined left-to-right and right-to-left training perspective. The study's findings demonstrate that bidirectionally trained language models can comprehend the context and flow of language more deeply than single-direction language models. The authors of the paper describe a unique method called Masked LM (MLM), which makes bidirectional training possible in models where it was previously not practicable.
In this article, we'll show you how to import a pre-trained Bert model from Hugging Face's transformers library and fine-tune it for your own NLP classification task.
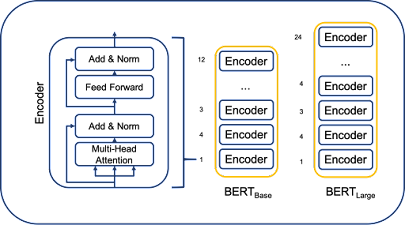
How BERT Works
Transformer is an attention mechanism that learns the contextual relationships between words (or subwords) in a text and is used by BERT. Transformer's basic design consists of two independent mechanisms: an encoder that reads the text input and a decoder that generates a job prediction. Only the encoder mechanism is required because BERT's aim is to produce a language model. In a publication published by Google, the precise operation of Transformer is described.
The Transformer encoder reads the entire sequence of words at once, in contrast to directional models, which read the text input sequentially (from right to left or left to right). Although it would be more accurate to describe it as non-directional, it is therefore thought of as bidirectional.
This trait enables the model to understand a word's context depending on all of its surroundings (left and right of the word).
A high-level explanation of the Transformer encoder can be found in the chart below. A series of tokens are used as the input and are first embedded into vectors before being processed by a neural network. The result is a series of vectors of size H, each of which corresponds to a token from the input with the same index.
The definition of a prediction target during language model training might be difficult. The following word in a sequence is frequently predicted by models (e.g., "The child arrived home from ___"), a directive approach that naturally restricts context learning. BERT employs two training techniques to overcome this obstacle:
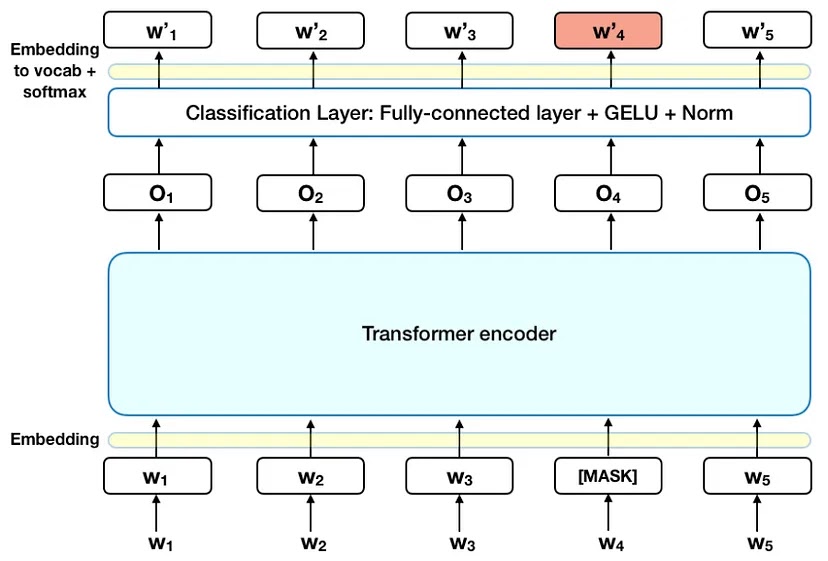
1. Masked LM
Word sequences are changed with a [MASK] token for 15% of the words in each sequence before being fed into the BERT. Based on the context offered by the other, non-masked, words in the sequence, the model then makes an attempt to forecast the original value of the masked words. Technically speaking, the output words' prediction calls for:
- The output of the encoder is added to a classification layer.
- By dividing the output vectors by the embedding matrix, the vocabulary dimension is created.
- Use softmax to determine the likelihood of each word in the lexicon.
2. Next Sentence Prediction (NSP)
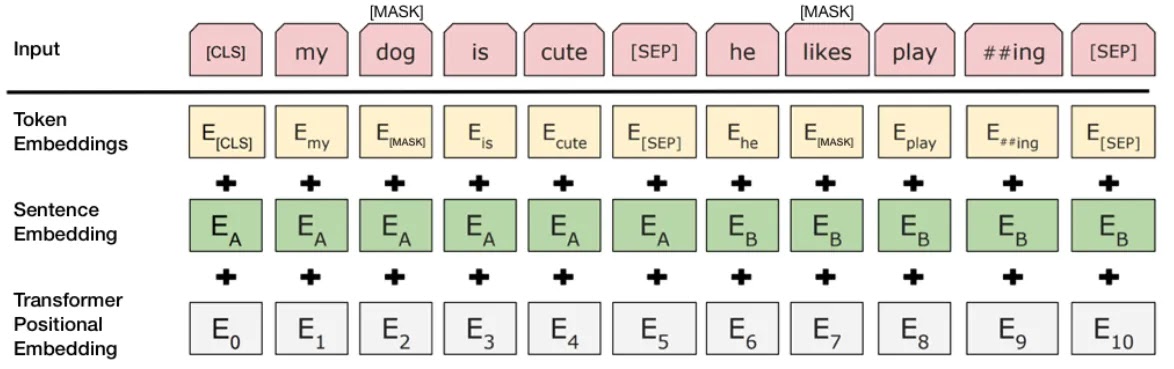
In the BERT training phase, the model learns to predict whether the second sentence in a pair will come after another in the original document by receiving pairs of sentences as input. During training, 50% of the inputs are pairs in which the second sentence is the next one in the original text, and in the remaining 50%, the second sentence is a randomly selected sentence from the corpus. The underlying presumption is that the second phrase will not be connected to the first.
Before entering the model, the input is processed as follows to aid the model in differentiating between the two sentences during training:
- The first sentence has a [CLS] token at the start, and each subsequent sentence has a [SEP] token at the end.
- Each token has a sentence embedding that designates Sentence A or Sentence B. Token embeddings with a vocabulary of 2 and sentence embeddings share a similar notion.
- Each token receives a positional embedding to denote its place in the sequence. The Transformer paper presents the theory and practice of positional embedding.

Importing a Pre-trained Bert Model
The first step is to install the 'transformers' library from Hugging Face by running 'pip install transformers' in your terminal. Then, you can import the Bert model by using the following code:
from transformers import BertTokenizer, BertForSequenceClassification
Here, 'BertTokenizer 'is used to preprocess the text data by tokenizing it into subwords, and 'BertForSequenceClassification' is a pre-trained Bert model that can be fine-tuned for sequence classification tasks.
# Load the tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# Text data to be preprocessed
text = "This is an example sentence for NLP classification."
# Tokenize the text
input_ids = tokenizer.encode(text, return_tensors='pt')In this example, we load the 'BertTokenizer' from the 'bert-base-uncased' pre-trained model, which uses lowercase letters. Then, we tokenize the text data and convert it into tensors, which are compatible with PyTorch.
Fine-Tuning the Bert Model
With the preprocessed text data, we can now fine-tune the Bert model for our NLP classification task. Here's an example of how to fine-tune the 'BertForSequenceClassification' model on a binary classification task:
# Load the Bert model for sequence classification
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# Define the binary classification task
labels = torch.tensor([1]).unsqueeze(0) # positive class
# Perform forward pass and get the logits
logits = model(input_ids, labels=labels)In this example, we load the 'BertForSequenceClassification' model from the 'bert-base-uncased' pre-trained model. Then, we define the binary classification task by creating a tensor with the desired label. Finally, we perform a forward pass through the model and get the logits, which are the raw scores that the model outputs for each class.
Training and Testing the Model
Now that we have the preprocessed text data and the fine-tuned Bert model, we can train and test the model on our NLP classification task. Here's an example of how to train and test the model using PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_inputs, train_labels = ... # Your training data
# Put the model in training mode
model.train()
# Loop over the training data
for input_ids, labels in zip(train_inputs, train_labels):
# Zero the gradients
optimizer.zero_grad()
# Perform a forward pass and get the logits
logits = model(input_ids, labels=labels)
# Compute the loss
loss = criterion(logits.view(-1, model.num_labels), labels)
# Perform a backward pass and update the weights
loss.backward()
optimizer.step()
# Put the model in evaluation mode
model.eval()
# Load the test data
test_inputs, test_labels = ... # Your test data
# Store the predictions and ground truth labels
predictions, true_labels = [], []
# Loop over the test data
with torch.no_grad():
for input_ids, labels in zip(test_inputs, test_labels):
# Perform a forward pass and get the logits
logits = model(input_ids, labels=labels)
# Get the predictions
_, preds = torch.max(logits, dim=1)
# Append the predictions and ground truth labels
predictions.append(preds.view(-1).cpu().numpy())
true_labels.append(labels.view(-1).cpu().numpy())
# Compute the accuracy
accuracy = sum([1 for p, t in zip(predictions, true_labels) if p == t]) / len(predictions)
print("Accuracy:", accuracy)The optimizer is an instance of the optimization algorithm that you want to use to update the model's weights. In this case, it can be an instance of any optimization algorithm from the 'torch.optim' library, such as 'Adam', 'SGD', 'Adagrad', etc.
In this example, we first load the training data and loop over it to update the model's weights. During the training loop, we perform a forward pass through the model, compute the loss, and perform a backward pass to update the weights. After training, we put the model in evaluation mode and load the test data. Then, we loop over the test data and perform a forward pass to get the logits, from which we get the predictions. Finally, we compute the accuracy by comparing the predictions with the ground truth labels.
Summary
In this Post, we showed you how to import a pre-trained Bert model from Hugging Face's transformers library, fine-tune it for your own NLP classification task, and train and test the model using PyTorch. With the power of transfer learning, fine-tuning pre-trained models like Bert can save you a lot of time and resources and achieve competitive results on NLP tasks. I hope this article was helpful and gave you a good starting point for your own NLP projects!
Comments
Post a Comment