
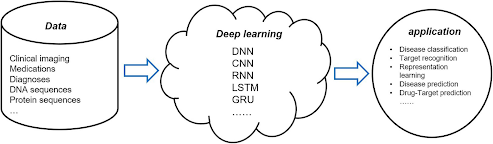
Machine learning is a subset of deep learning (DL), commonly referred to as deep structured learning or hierarchical learning. It is loosely based on how neurons interact with one another in animal brains to process information. Artificial neural networks (ANNs), a layered algorithmic design used in deep learning (DL), evaluate data to mimic these connections. A DL algorithm can "learn" to identify correlations and connections in the data by examining how data is routed through an ANN's layers and how those levels communicate with one another.
Due to these features, DL algorithms are cutting-edge tools with the potential to transform healthcare. The most prevalent varieties in the sector have a range of applications.
Deep learning is a growing trend in healthcare artificial intelligence, but what are the use cases for the various types of deep learning?
Deep learning and transformers have been used in a variety of medical applications. Here are some examples:
Diagnosis and treatment: Deep learning algorithms have been used to analyze medical images, such as X-rays, CT scans, and MRIs, to assist with diagnosis and treatment planning. For example, a deep learning algorithm might be trained to identify abnormalities in an MRI scan that are indicative of a particular disease or condition.
Predictive modeling: Deep learning algorithms can be used to build predictive models that can help forecast the likelihood of a particular outcome, such as the likelihood of a patient developing a particular disease or condition. These models can be used to guide treatment decisions and to identify individuals who may be at high risk for certain conditions.
Medical Natural language processing: Transformers, a type of deep learning algorithm, have been used to process and analyze large amounts of medical text data, such as electronic health records, to extract relevant information and to identify patterns and trends. This can be used to improve the accuracy of diagnoses, to identify potential treatment options, and to predict patient outcomes.
Drug discovery: Deep learning algorithms have been used to identify potential new drugs by analyzing the chemical structure of compounds and predicting their potential efficacy and side effects. This can help reduce the time and cost associated with traditional drug discovery processes.
SOTA models used in Medicine and Healthcare
There are several state-of-the-art deep learning models that have been used in medical image classification and disease diagnosis, including:
Convolutional neural networks (CNNs): CNNs are a type of deep learning model that are particularly well-suited for image classification tasks. They have been widely used in medical imaging applications, such as detecting abnormalities in X-ray images and identifying specific structures in medical images.
Recurrent neural networks (RNNs): RNNs are a type of deep learning model that are well-suited for tasks involving sequential data, such as time series data or text data. They have been used in medical imaging applications to identify patterns in sequential medical images, such as in dynamic contrast-enhanced MRI scans.
Generative adversarial networks (GANs): GANs are a type of deep learning model that consists of two neural networks: a generator network and a discriminator network. They have been used in medical imaging applications to synthesize new medical images, such as CT scans, from a limited number of available images. This can be useful for generating additional training data for other deep-learning models or for improving the generalization of models to new patient populations.
Transformer-based models: these attention-based models, such as transformers, have been used in medical imaging applications to analyze and classify large amounts of medical text data, such as electronic health records. They have also been used to analyze medical images and extract relevant information from them.
Overall, these are just a few examples of the deep learning models that have been used in medical image classification and disease diagnosis. There are many other models and approaches that have been used in these applications, and new models and approaches are constantly being developed.
Examples of deep learning models being applied in Medicine and Healthcare
Here are a few examples of common structures that are used in medicine and healthcare:
Convolutional neural networks (CNNs): CNNs are a type of deep learning model that are particularly well-suited for image classification tasks. They consist of multiple layers of convolutional and pooling layers, followed by one or more fully connected layers. The convolutional layers apply a set of learnable filters to the input image, and the pooling layers down-sample the output of the convolutional layers to reduce the dimensionality of the feature maps. The fully connected layers process the output of the pooling layers and generate a prediction for the input image.
Encoder-Decoder networks: Encoder-decoder networks are a type of deep learning model that are often used for image segmentation tasks. They consist of an encoder network and a decoder network. The encoder network processes the input image and generates a set of feature maps, which are then passed to the decoder network. The decoder network processes the feature maps and generates a segmentation mask for the input image, indicating the boundaries of the different structures or objects in the image.
Inception-v3: Inception-v3 is a CNN that was developed by Google and has been used in a variety of medical imaging applications, including chest X-ray classification and breast cancer diagnosis. It consists of multiple layers of convolutional and pooling layers, with inception modules interleaved between the layers. The inception modules apply a set of different filter sizes to the input image, which allows the model to capture different scales of information.
Mask R-CNN: Mask R-CNN is a CNN that was developed for object detection and instance segmentation tasks. It has been used in medical imaging applications to identify and segment specific structures in medical images, such as tumors or organs. It consists of a backbone network, a region proposal network, and a classification and segmentation head. The backbone network processes the input image and generates a set of feature maps, which are then passed to the region proposal network. The region proposal network generates a set of bounding boxes around potential objects in the image, which are then passed to the classification and segmentation head. The classification and segmentation head processes the bounding boxes and generates class predictions and segmentation masks for each object.
ResNet: ResNet is a CNN that was developed by Microsoft and has been used in a variety of medical imaging applications, including chest X-ray classification and skin cancer diagnosis. It consists of multiple layers of convolutional and pooling layers, with residual connections between the layers. The residual connections allow the model to more easily learn complex relationships between the input and output, which can improve the model's performance on tasks with large amounts of data.
BERT: BERT is a transformer model that was developed by Google and has been used in a variety of natural language processing tasks, including medical text classification and entity extraction. It consists of multiple layers of self-attention and feedforward layers, which allow the model to process and understand the context and relationships between words in a text.
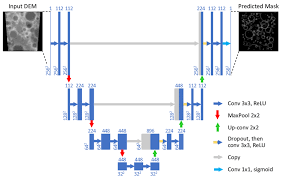
U-Net: U-Net is a specific type of encoder-decoder network that has been widely used in medical image segmentation tasks. It consists of a contracting path and an expanding path, with skip connections between the two paths. The contracting path processes the input image and generates a set of feature maps, which are then passed to the expanding path. The expanding path processes the feature maps and generates a segmentation mask for the input image, using the skip connections to incorporate information from the contracting path.
Comments
Post a Comment