
Training a neural network can sometimes be difficult due to various reasons. Some of these reasons include:
• Insufficient data: Training a neural network requires a large amount of data, and if the dataset is small or lacks diversity, the network may not be able to learn effectively.
• Poor data quality: The quality of the training data can also impact the network's ability to learn. If the data is noisy, contains errors, or is not representative of the real-world data the network will be used on, the network may not be able to learn effectively.
• Overfitting: Overfitting occurs when a neural network learns the patterns in the training data too well and is not able to generalize to new, unseen data. This can make the network perform poorly on real-world data.
• Local minima: Neural networks can get stuck in local minima, which are suboptimal solutions to the training problem. This can make it difficult for the network to find the global optimum solution.
• Vanishing or exploding gradients: When training deep neural networks, the gradients of the loss function with respect to the network weights can become very small or very large, making it difficult for the network to learn effectively.
These challenges can make training neural networks difficult, but there are various techniques and strategies that can help address these challenges, such as regularization, data augmentation, Batch Normalization (BN), and learning rate schedule.
In this post, we will be discussing Batch Normalization:
- What is it and why is it important!
- How does it work!
- How is it implemented in Python?
- Its effects on the learning process of CNN
What is Batch Normalization (BN) and why is it important!
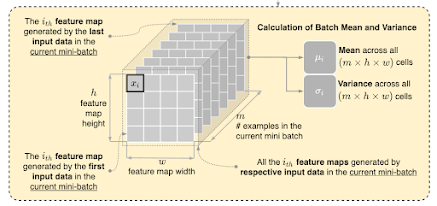
How does it work!
The mathematical process of batch normalization (BN) can be described as follows:
1. Given a mini-batch of data x with m examples, the batch normalization layer first calculates the mean mu and variance sigma^2 of the mini-batch.
2. The layer then normalizes the input data by subtracting the mean and dividing by the square root of the variance, resulting in a normalized tensor x_hat.
3. Finally, the layer scales and shifts the normalized data using two learnable parameters, gamma, and beta, respectively. This results in the output of the batch normalization layer y.
Mathematically, this process can be written as:
mu = 1/m * sum(x) sigma^2 = 1/m * sum((x - mu)^2) x_hat = (x - mu) / sqrt(sigma^2 + epsilon) y = gamma * x_hat + beta
BN Implementation in Python (Tensorflow)
To implement batch normalization in TensorFlow, you can use the tf.keras.layers.BatchNormalization layer. Here's an example of how to use it:
import tensorflow as tf # Define the input tensor input_tensor = tf.keras.Input(shape=(128, 256)) # Apply the convolutional layer with 64 filters and a kernel size of 3 x = tf.keras.layers.Conv1D(64, 3)(input_tensor) # Apply batch normalization to the convolutional layer output x = tf.keras.layers.BatchNormalization()(x) # Create a model from the input and output tensors model = tf.keras.Model(inputs=input_tensor, outputs=x)
BN Implementation in Python (Pytorch)
import torch import torch.nn as nn n = nn.BatchNorm1d(102) # Without Learnable Parameters n = nn.BatchNorm1d(102, affine=False) inputval = torch.randn(22, 102) outputval = n(input) print(outputval)
BN's effects on the learning process of CNN
import torch import os from torch import nn from torchvision.datasets import CIFAR10 from torch.utils.data import DataLoader from torchvision import transforms import torch.nn.functional as F from torch.autograd import Variable class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x model = Net()if __name__ == '__main__': torch.manual_seed(44) # Prepare CIFAR-10 dataset dataset = CIFAR10(os.getcwd(), download=True, transform=transforms.ToTensor()) trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1) optimizer = torch.optim.Adam(model.parameters()) criterion = nn.CrossEntropyLoss() # Define the loss function and optimizer lossfunction = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) # Run the training loop for epoch in range(0, 5): # Print epoch print(f'Starting epoch {epoch+1}') currentloss = 0.0 # Iterate over the DataLoader for training data for i, data in enumerate(trainloader, 0): # Get inputs inputs, targets = data optimizer.zero_grad() # Perform forward pass outputs = model(inputs) # Compute loss loss = lossfunction(outputs, targets) # Perform backward pass loss.backward() # Perform optimization optimizer.step() # Print statistics currentloss += loss.item() if i % 502 == 499: print('Loss after mini-batch %5d: %.3f' % (i + 1, currentloss / 502)) currentloss = 0.0 print('Training process has been finished.')
Loss after mini-batch 500: 1.455 Training process has been finished. Loss after mini-batch 1002: 1.459 Training process has been finished. Loss after mini-batch 1504: 1.459 Training process has been finished. Loss after mini-batch 2006: 1.470 Training process has been finished. Loss after mini-batch 2508: 1.461 Training process has been finished. Loss after mini-batch 3010: 1.470 Training process has been finished. Loss after mini-batch 3512: 1.445 Training process has been finished. Loss after mini-batch 4014: 1.424 Training process has been finished. Loss after mini-batch 4516: 1.436 Training process has been finished
import torch
import os
from torch import nn
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
from torchvision import transforms
import torch.nn.functional as F
from torch.autograd import Variable
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
nn.BatchNorm2d(6)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
nn.BatchNorm2d(84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()
if __name__ == '__main__':
torch.manual_seed(44)
# Prepare CIFAR-10 dataset
dataset = CIFAR10(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
# Define the loss function and optimizer
lossfunction = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 10):
# Print epoch
print(f'Starting epoch {epoch+1}')
currentloss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
optimizer.zero_grad()
# Perform forward pass
outputs = model(inputs)
# Compute loss
loss = lossfunction(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
currentloss += loss.item()
if i % 502 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, currentloss / 502))
currentloss = 0.0
print('Training process has been finished.')Loss after mini-batch 500: 1.438
Training process has been finished.
Loss after mini-batch 1002: 1.433
Training process has been finished.
Loss after mini-batch 1504: 1.425
Training process has been finished.
Loss after mini-batch 2006: 1.415
Training process has been finished.
Loss after mini-batch 2508: 1.434
Training process has been finished.
Loss after mini-batch 3010: 1.420
Training process has been finished.
Loss after mini-batch 3512: 1.463
Training process has been finished.
Loss after mini-batch 4014: 1.411
Training process has been finished.
Loss after mini-batch 4516: 1.399
Training process has been finished.
Comments
Post a Comment